Данные для SpeechKit Brand Voice Lite
SpeechKit Brand Voice Lite позволяет создать свой уникальный голос на основе минимума размеченных аудиозаписей. В результате вы получите идентификатор модели, к которой сможете обращаться из своих приложений через API.
Важно
Функциональность доступна только в регионе Россия.
Какие данные нужны для обучения
Чтобы создать свой голос SpeechKit Brand Voice Lite, необходимо подготовить датасет для обучения — аудиозаписи и соответствующие им тексты. Каждая аудиозапись должна точно соответствовать приведенному тексту.
Объем данных для обучения модели зависит от особенностей дикции диктора и назначения создаваемого голоса. Так, голос для озвучки художественной литературы потребует больше данных, чем голос для голосового робота. Минимальный объем чистого аудио без учета тишины в начале и конце каждого файла — 30 минут, рекомендуемый — 60 минут, хороший — 90 минут и более. Для создания голоса с несколькими амплуа понадобится отдельно записать датасет для каждого.
Совет
Результат обучения голосовой модели SpeechKit Brand Voice Lite напрямую зависит от обучающих данных. Чтобы получить качественный голос SpeechKit Brand Voice Lite, выполняйте все приведенные рекомендации для текстов и аудиозаписей.
Как минимум 30% обучающих данных должны содержать вопросы, чтобы обученный голос мог синтезировать вопросительную интонацию в тексте. Вы можете использовать уже готовый набор фраз от команды SpeechKit или самостоятельно подготовить тексты для озвучивания. Рекомендации по созданию и оформлению текстов для обучения смотрите в разделе Требования к текстам.
Независимо от того, записываете вы готовый набор фраз или подготавливаете свои данные, обязательно включите в обучающий датасет следующую фразу: Я даю согласие на использование своего голоса в сервисе Спичкит.
Вы можете загрузить датасет со всеми аудиозаписями и расшифровками в виде одного архива, загрузить аудиофайлы по одному или записать аудио для каждой фразы в консоли управления через браузер. В любом случае обязательно следуйте рекомендациям для записи аудио и прослушайте все аудио, чтобы убедиться в качестве исходных данных для обучения голосовой модели. После запуска обучения исправить датасет не получится.
Требования к текстам
Команда SpeechKit предоставляет уже готовый набор текстов, которые вам необходимо только озвучить. Он содержит повествовательные, вопросительные и восклицательные фразы и подойдет в большинстве случаев для создания русскоязычных голосов. Также вы можете самостоятельно подготовить тексты для записи аудио, однако убедитесь, что они соответствуют следующим требованиям:
- Тексты не должны содержать грамматических ошибок.
- Рекомендуемая длина фразы — не более 250 символов.
- Все фразы должны быть полными, без обрывов на полуслове.
"..ть Время! Разве такое ему может понравиться! Если б ты с ним не ссорилась, могла бы просить у него все, что хо."
-
При записи речи на русском языке обязательно указывайте букву «ё» в расшифровке. Использование «е» вместо «ё» в любых текстах для синтеза недопустимо.
-
В словах-омографах, где ударение может быть поставлено неоднозначно, явно указывайте ударную гласную знаком
+.«Он вставил ключ в зам+ок.», ударение падает на второй слог.
«Михайловский з+амок — главный корпус Пушкинского музея.», ударение падает на первый слог. -
Строки текста для синтеза не должны содержать цифр и сокращений вида «ул. Строителей, д.15 к.3» или «13 руб 10 коп». Цифры и числа записывайте прописью, сокращения — полностью раскрывайте.
Улица Строителей, дом пятнадцать, корпус три.
Тринадцать рублей десять копеек. -
В вопросительных предложениях укажите, на какое слово приходится **логическое ударение** — вопросительная интонация предложения.
Предложение «Кот пошел в лес?» можно прочитать тремя разными способами:
- **Кот** пошел в лес? — со смыслом «Кто пошел в лес? Это был действительно кот?»
- Кот **пошел** в лес? — со смыслом «Кот пошел или побежал?» или «Было ли совершено само действие? Кот ушел или нет?»
- Кот пошел **в лес**? — со смыслом «Куда или за чем пошел кот? В лес, в школу, за колбасой?»
Во всех предложениях логическое ударение выделяет основной смысл предложения.
Рекомендации для записи аудио
Записывайте аудио в тихой комнате без посторонних шумов. Звук вентилятора, кондиционера или холодильника, шум улицы, фоновая музыка и эхо будут слышны на записи и сильно отразятся на качестве создаваемого голоса. Идеальным местом будет комната, оборудованная акустическими панелями. Если вы записываете свой голос в бытовых условиях, снизить эхо помогут мягкие поверхности и мебель: ковер, мягкий диван и т. д.
Для записи аудио не обязательно использовать профессиональное оборудование. Если у вас нет студийного микрофона, используйте встроенный микрофон ноутбука, смартфон или гарнитуру. Режим шумоподавления в большинстве гарнитур обрезает начало и конец фразы, поэтому рекомендуем отключить его. Не меняйте настройки аппаратуры до окончания записи. Расстояние до микрофона должно быть одинаковым для всех аудио.
На время записи отключите используемое устройство от электросети, если это возможно: в процессе зарядки аккумулятора могут возникать аудиопомехи. Также отключите звуковые уведомления и переведите смартфон в авиарежим, чтобы посторонние звуки не попали на запись.
Записывайте аудио с максимально возможным качеством без сжатия. Если для записи вы используете специальные программы, убедитесь, что сжатие файлов и дополнительные фильтры отключены.
Перед записью убедитесь, что вы не голодны и не испытываете жажду, нет лишнего слюноотделения или сухости во рту. Уберите шуршащие предметы и постарайтесь лишний раз не двигать руками и ногами во время записи. Расслабьтесь, выпрямите спину и шею, дышите глубоко и свободно. Звуки вашего дыхания не должны перекрывать аудио на записи.
Читайте текст так, чтобы он звучал максимально естественно и органично. Эмоции должны соответствовать произносимому тексту. Сохраняйте интонацию при записи всех примеров для одного амплуа. Подробные рекомендации о записи амплуа смотрите в разделе Рекомендации для записи амплуа.
Если вы ошиблись в произношении, перезапишите всю фразу, а не пытайтесь исправиться в том же аудио. Неточности, микроповторы, оговорки и замены слов недопустимы. Любые дефекты дикции в записях, на основе которых работает модель синтеза, значительно снижают качество синтезируемой речи.
После записи фразы прослушайте получившееся аудио. Убедитесь, что все слова произнесены четко и внятно, в начале и в конце аудио есть небольшие отрезки тишины, на фоне нет посторонних звуков.
Требования к аудиозаписям
Если вы записываете аудио с помощью специальных программ, а не в консоли управления через браузер, убедитесь, что они соответствуют следующим требованиям:
| Требование | Значение |
|---|---|
| Частота дискретизации | 48 кГц |
| Глубина аудио (audio bit depth) | 16 бит PCM |
| Количество каналов | 1 (моно) |
| Формат | WAV |
| Продолжительность | ≤ 15 секунд |
| Тишина в начале и в конце | 100–200 миллисекунд |
Важно
В каждой аудиозаписи должна быть полностью произнесенная фраза из одного или нескольких предложений длительностью не более 15 секунд. Текстовая расшифровка в таблице должна полностью совпадать с текстом на аудиозаписи.
В каждой аудиозаписи в начале и в конце должны присутствовать интервалы тишины, обрезанные звуки и слова недопустимы. Нельзя взять аудиозапись подкаста и нарезать ее на отрезки по 15 секунд: в этом случае границы аудиозаписей будут попадать на середину слова или фразы и не будут соответствовать логическим фразам. Обучить качественную модель на таких данных не получится.
Пример правильно подготовленной аудиозаписи: в начале и в конце аудио есть несколько миллисекунд тишины, фраза произнесена полностью.
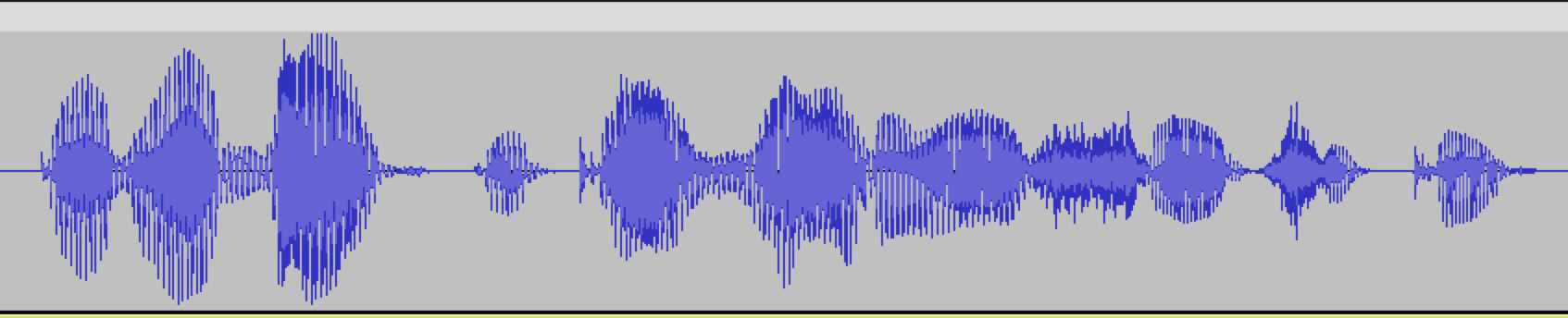
Пример плохой аудиозаписи: в начале и в конце аудио нет интервалов тишины, начало и конец фразы обрезаны.
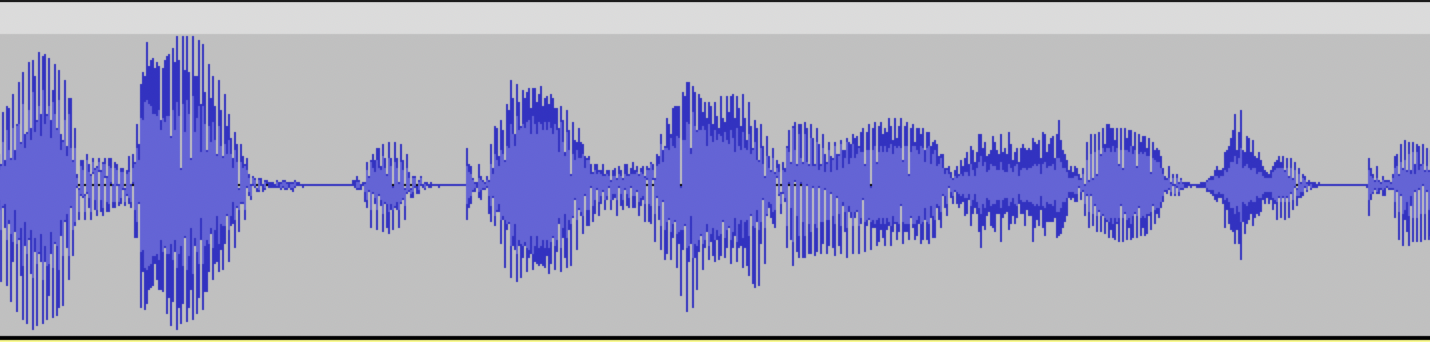
Такие аудиозаписи будут иметь искажения и не подойдут для обучения модели.
Как создать голос
- В консоли управления выберите каталог, в котором вы будете работать с сервисом.
- В списке сервисов выберите SpeechKit.
- На панели слева нажмите Brand Voice Lite.
- Нажмите Создать голос.
- Нажмите Создать датасет и выберите Записать аудиофайлы.
- Выберите данные для записи: нажмите Использовать готовый шаблон или Загрузить собственные тексты.
- В строке с нужным текстом нажмите Записать аудио ⟶ Записать, а затем прочитайте текст вслух.
- Нажмите кнопку , чтобы прослушать результат.
- Если запись не содержит посторонних звуков, фраза записана полностью, и ее хорошо слышно, нажмите Сохранить. Чтобы повторить запись, нажмите Записать заново.
- Запишите аудио для остальных текстов.
-
В блоке Использование голоса:
- Ознакомьтесь с условиями использования сервиса SpeechKit и подтвердите, что ознакомлены.
- Подтвердите, что имеете письменное согласие лица, чей голос используется на аудиозаписи, на использование данной аудиозаписи для создания и использования синтеза речи.
- Нажмите Создать голос, чтобы запустить создание голоса.
- В консоли управления выберите каталог, в котором вы будете работать с сервисом.
- В списке сервисов выберите SpeechKit.
- На панели слева нажмите Brand Voice Lite.
- Нажмите Создать голос.
- Нажмите Создать датасет и выберите Добавить аудиофайлы.
- Выберите тексты, по которым записывались аудиофайлы: нажмите Использовать готовый шаблон или Загрузить собственные тексты.
- В строке с нужным текстом нажмите Добавить аудиофайл.
- Добавьте аудиофайлы для остальных текстов.
-
В блоке Использование голоса:
- Ознакомьтесь с условиями использования сервиса SpeechKit и подтвердите, что ознакомлены.
- Подтвердите, что имеете письменное согласие лица, чей голос используется на аудиозаписи, на использование данной аудиозаписи для создания и использования синтеза речи.
- Нажмите Создать голос, чтобы запустить создание голоса.
-
В консоли управления выберите каталог, в котором вы будете работать с сервисом.
-
В списке сервисов выберите SpeechKit.
-
Нажмите Создать голос.
-
Нажмите Создать датасет и выберите Загрузить ZIP-архив.
-
Перетащите ZIP-архив в область загрузки.
ZIP-архив с датасетом для дообучения должен содержать:
- Аудиозаписи в формате WAV.
- Таблицу в формате TSV в кодировке UTF-8, содержащей текстовые расшифровки аудиозаписей из архива. Таблица должна состоять из двух колонок без заголовков:
- имя файла с аудиозаписью, на которой диктор произносит текст;
- строка, содержащая дословную расшифровку аудиозаписи.
-
В блоке Использование голоса:
- Ознакомьтесь с условиями использования сервиса SpeechKit и подтвердите, что ознакомлены.
- Подтвердите, что имеете письменное согласие лица, чей голос используется на аудиозаписи, на использование данной аудиозаписи для создания и использования синтеза речи.
-
Нажмите Создать голос, чтобы запустить создание голоса.
Если вы используете шаблон от команды SpeechKit, в начало каждой строки добавьте название файла с соответствующей аудиозаписью и удалите строку с заголовком таблицы.
Пример подготовленных данных
Заголовок таблицы приведен для наглядности, в файле для загрузки он должен отсутствовать.
| recordings | text |
|---|---|
| 1.wav | Книги собирают жемчужины человеческой мысли и передают их потомкам. |
| 2.wav | Мы предлагаем вам замечательную книгу! |
| 3.wav | Книга рекомендована школьникам от пяти лет. |
Статусы голоса
Как только вы запустите создание голоса, он появится в списке доступных голосов в разделе Brand Voice Lite. Процесс создания займет несколько дней, в это время голос будет находиться в статусе Creating. Когда процесс будет завершен и голос станет доступным для тестирования, статус изменится на Trial. В течение 7 дней вы можете использовать голос бесплатно в SpeechKit Playground и синтезировать речь по API, оплачивая только сами запросы (правила тарификации). Когда пробный период истечет, голос будет перенесен в архив, получит статус Archived, и вы не сможете использовать его. Хостинг архивных голосов не тарифицируется.
Если созданный голос вас устраивает, вы можете его активировать, не дожидаясь завершения пробного периода. Также вы можете активировать голос, находящийся в архиве:
- В консоли управления выберите каталог, в котором вы будете работать с сервисом.
- В списке сервисов выберите SpeechKit.
- На панели слева нажмите Brand Voice Lite.
- Выберите голос и перейдите на его страницу.
- В правом верхнем углу нажмите Активировать.
После активации голос получит статусActiveи станет доступен через API и в SpeechKit Playground без ограничений. Начнется тарификация хостинга.
Если голос вам больше не нужен, вы можете переместить его в архив.
Как обратиться к голосу в дообученной модели
Созданный голос будет доступен в SpeechKit Playground и через API v3. Чтобы использовать голос через API, укажите полученный идентификатор модели в настройках параметров синтеза:
{
...
"model": "tts://<идентификатор_каталога>/bvss-v1/latest@<идентификатор_голоса>/?<идентификатор_модели>"
...
}
Пример
Используйте IAM-токен для аутентификации от имени аккаунта на Яндексе или федеративного аккаунта. У аккаунта должна быть роль ai.speechkit-tts.user. Другие варианты аутентификации смотрите в разделе Аутентификация в API SpeechKit.
Чтобы повторить пример, потребуется утилита jq для работы с файлами JSON.
-
Создайте файл
tts_rest.jsonс параметрами запроса:{ "text": "Привет! Я Яндекс Спичк+ит. Я могу превратить любой текст в речь. Теперь и в+ы - можете!", "model": "tts://<идентификатор_каталога>/bvss-v1/latest@<идентификатор_голоса>/?<идентификатор_модели>" }Где:
text— синтезируемый текст;model— дообученная модель, к которой вы обращаетесь.
-
В терминале выполните запрос, указав IAM-токен и идентификатор каталога, который вы будете использовать для работы с SpeechKit:
export FOLDER_ID=<идентификатор_каталога> export IAM_TOKEN=<IAM-токен> --header "Authorization: Bearer $IAM_TOKEN" \ --header "x-folder-id: $FOLDER_ID" \ --data @tts_rest.json https://tts.api.ml.yandexcloud.kz:443/tts/v3/utteranceSynthesis | \ jq -r '.result.audioChunk.data' | \ while read chunk; do base64 -d <<< "$chunk" >> audio_my.wav; doneГде:
FOLDER_ID— идентификатор каталога, на который у вашего аккаунта есть рольai.speechkit-tts.userили выше. Если вы используете сервисный аккаунт, передавать в запросе идентификатор каталога не нужно.IAM_TOKEN— IAM-токен вашего аккаунта на Яндексе или федеративного аккаунта.
Синтезированная речь вернется в кодировке Base64 и будет записана в файл
audio_my.wav.