В тарифном плане Business вы можете стилизовать интерфейс дашборда, встраивать чарты во внешние системы (CRM, корпоративные порталы, личные кабинеты) и отслеживать статистику использования сервиса. Мы гарантируем приоритетную поддержку и SLA.

Аналитика в Yandex DataLens за пределами CSV: визуализируем данные из Greenplum®
Рассказываем о настройке Managed Service for Greenplum®: загрузим в эту СУБД 6 гигабайт данных и подключим DataLens для визуализации. Инструкция поможет настроить обработку больших объёмов данных для аналитики движения товаров или банковских операций.
21 июня 2024 г.
20 минут чтения
В одной из предыдущих статей мы рассказывали о том, как использовать управляемую базу данных ClickHouse® для анализа данных в Yandex DataLens. Эта связка позволяет оптимизировать загрузку, хранение и OLAP‑обработку до десятков терабайт данных, опираясь на денормализованную колоночную структуру. Но если хранение и обработка терабайтов данных подразумевает сложную структуру, параллельную обработку вкупе с интенсивной записью и транзакционностью, то может быть целесообразно использовать такую СУБД, как Greenplum.
Особенности Greenplum
В Greenplum память физически разделена (массивно‑параллельная архитектура MPP), работает на группе серверов и может хранить строчные и колоночные таблицы. В Greenplum есть резервированный мастер‑хост, к которому подключаются клиенты, и множество сегмент‑хостов, которые хранят и обрабатывают данные.
На хостах располагаются:
-
сегменты — самостоятельные системы управления; мастер‑сегмент на мастер‑хосте принимает подключения клиентов, координирует действия и выдаёт результаты запросов;
-
резервный мастер на мастер‑хосте с репликой основного;
-
первичные сегменты и сегменты‑зеркала, расположенные на сегмент‑хостах.
На каждом сегмент‑хосте может быть несколько сегментов, при этом у всех данных в Greenplum есть реплика. Данные распределяются по сегментам для адаптации алгоритмов обработки. Пользователи работают только с мастер‑сегментом.
Greenplum даёт возможность работать с большими объёмами данных разных типов, поддерживает сложные запросы и написание функций на множестве языков программирования, например C, C++, PHP, Ruby, Python.
С помощью Greenplum крупные компании обрабатывают десятки терабайт информации: Skyeng строит аналитику об обучении 150 тысяч своих студентов, «Ренессанс страхование» анализирует информацию о страховых услугах для 5 миллионов клиентов, «Леруа Мерлен» собирает и анализирует информацию в 100 различных базах данных, включающих веб‑аналитику, данные по товарам и потребительским корзинам.
Отметим, что это решение подойдёт, если вам нужны сложные соединения фактографических таблиц и справочных данных. Например, при аналитике движения товаров или банковских операций.
Если самостоятельное развёртывание и, главное, обслуживание Greenplum кажется сложным, то можно использовать управляемый сервис Yandex Cloud. Ниже рассмотрим процесс развёртывания и использования Managed Service for Greenplum.
Этап 1. Создаём и настраиваем кластер Greenplum (если у вас уже есть облако и настроен кластер, то пропустите этот этап)
- Создайте аккаунт и облако в Yandex Cloud.
-
В консоли управления в правом верхнем углу нажмите на кнопку Создать ресурс и в выпадающем списке выберите Кластер Greenplum.
-
В окне настроек кластера оставьте параметры по умолчанию или задайте нужные вам.
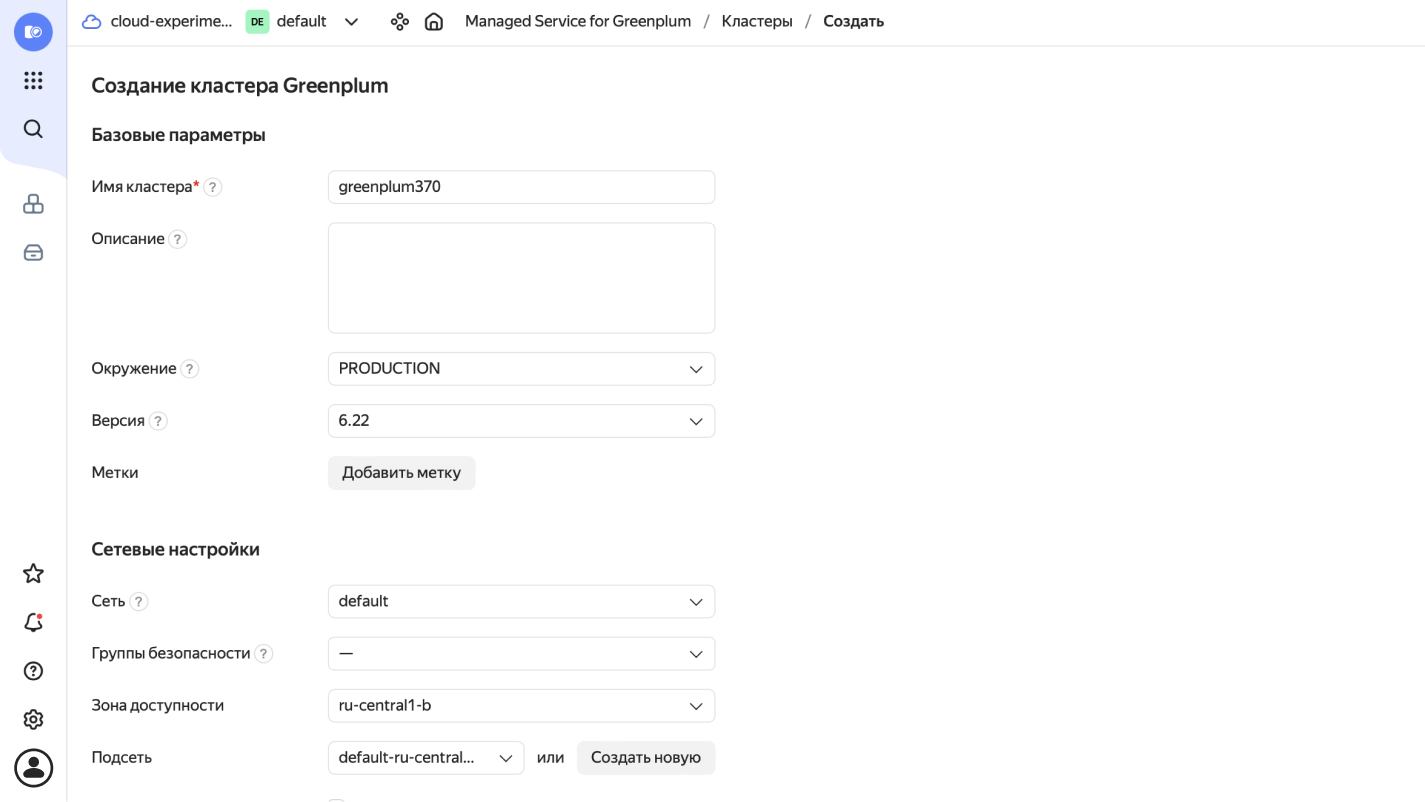
- Для совместной работы DataLens и Greenplum нужно оставить включённым режим доступности из DataLens и публичный доступ. Для этого в разделе Дополнительные настройки поставьте галочку Доступ из DataLens.
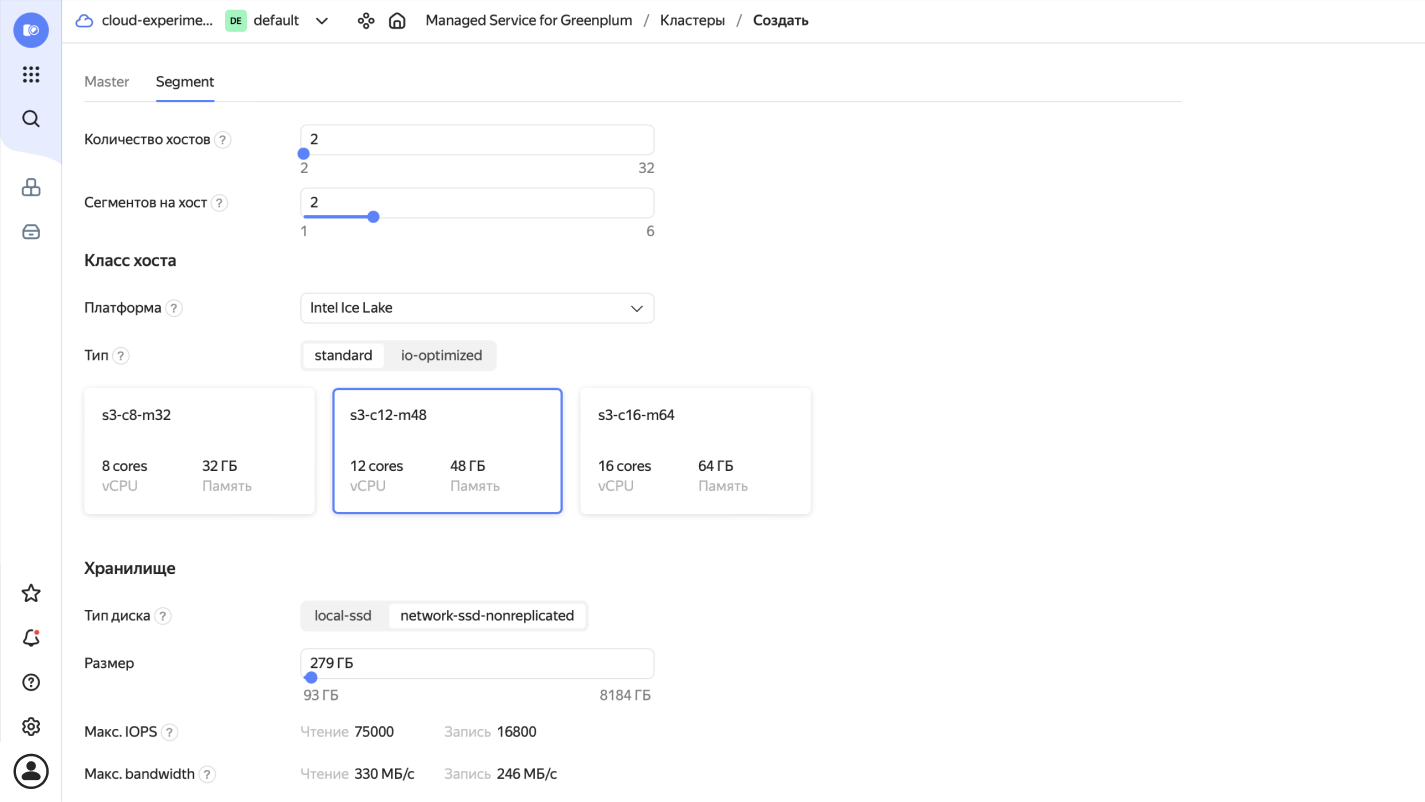
- Выберите ресурсы для мастер- и сегмент‑хостов.
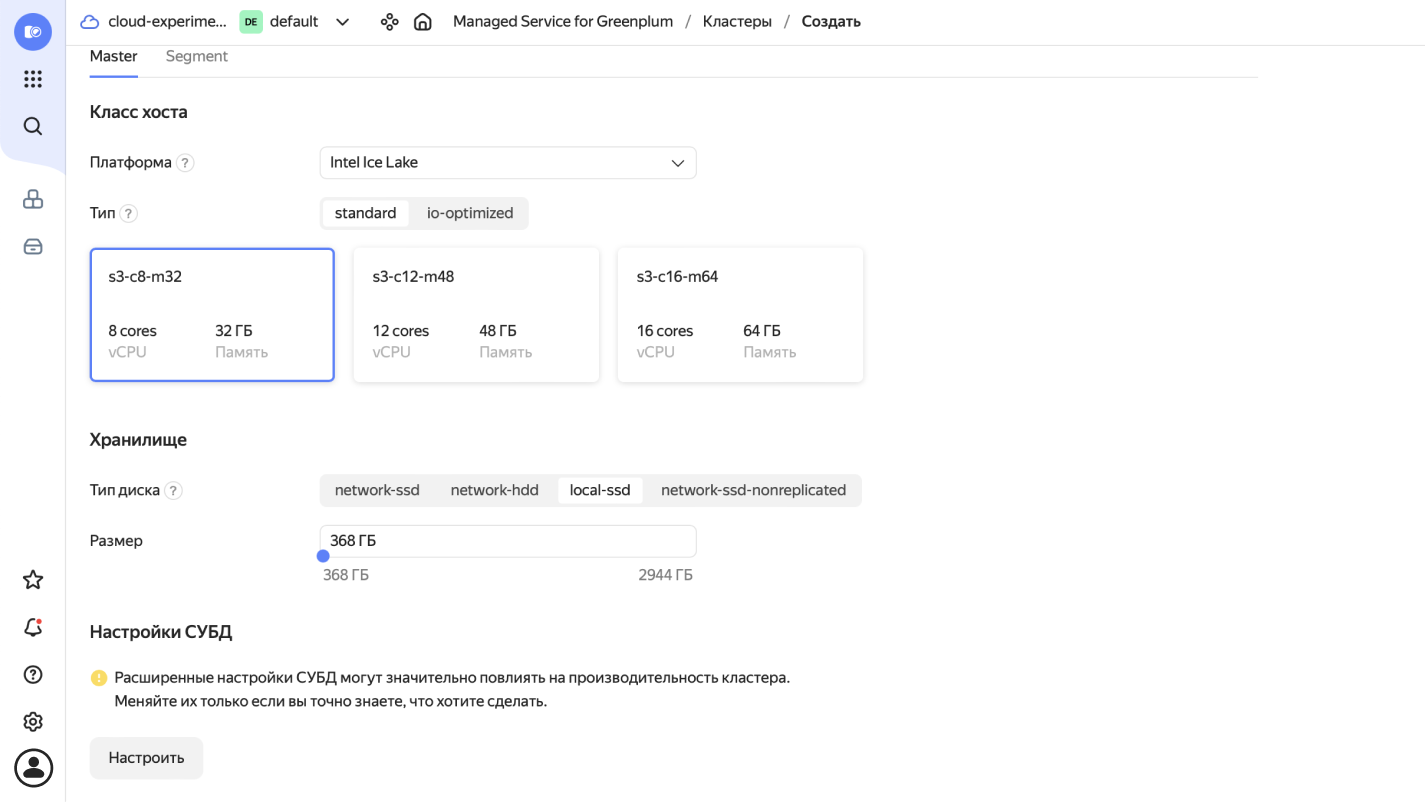
В минимальном наборе используется 4 хоста:
-
мастер‑хост (сервер, на котором работает основной инстанс);
-
реплика мастер‑хоста;
-
два сегмент‑хоста (сервер, на котором работают один или несколько сегментов) по 8 ядер, 32 ГБ оперативной памяти, по 2 сегмента на каждом. Доступное количество сегментов зависит от числа ядер.
Это достаточно скромная конфигурация для Greenplum, и его возможности в промышленном использовании гораздо шире. Подробнее о настройках кластера можно узнать из документации и курса Практикума по работе с Managed Service for Greenplum.
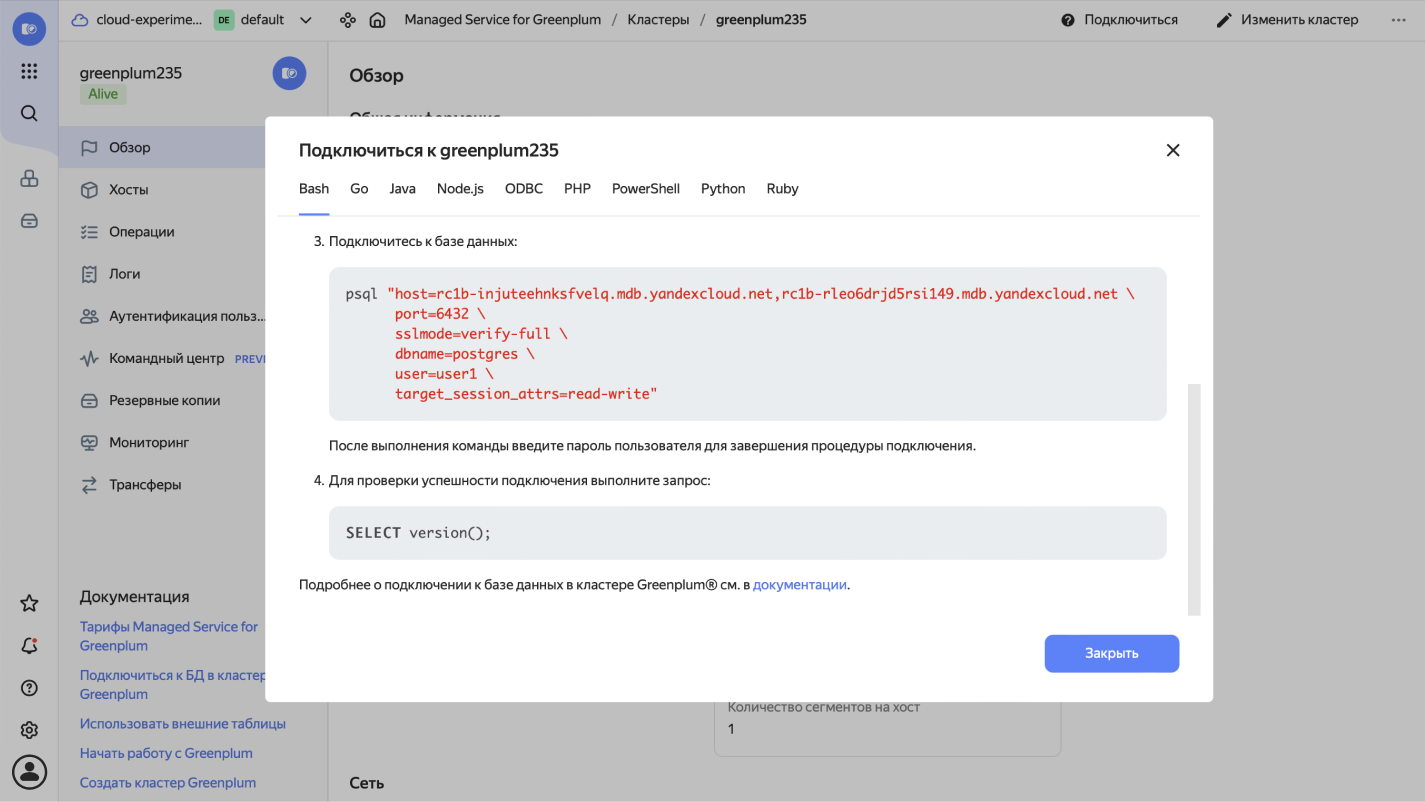
После создания кластера по кнопке Подключиться будут доступны параметры и примеры подключения.
Этап 2. Создаём первые таблицы и справочники
В основе Greenplum лежит PostgreSQL, и методы их подключения схожи. Для загрузки данных из больших файлов рекомендуем использовать утилиту psql. SQL‑диалект также во многом схож, но имеет ряд дополнений, учитывающих особенности архитектуры и обработки данных.
Создадим абстрактную БД движения товаров. Для нашего примера выгрузили реальные данные, в которых изменили названия на синтетические и исказили значения. Вы можете сгенерировать свои данные под аналогичную структуру.
Так будет выглядеть DDL‑код для создания таблицы под основной объём данных по поставкам товаров в магазины:
CREATE TABLE public.shipping (
dt timestamp without time zone not null,
shopcode bigint not null,
sku character(32) not null,
groupcode character(32) not null,
categorycode character(32) not null,
qnty integer,
weight numeric(15,3),
party character(32),
shiftdate timestamp without time zone)
WITH (
appendonly = true,
orientation = column, –колоночный тип
compresstype = zstd,
compresslevel = 1
)
DISTRIBUTED BY (sku, dt)
PARTITION BY RANGE (dt)
(START ('2022-01-01 00:00:00')
END ('2025-01-01 00:00:00')
EVERY (INTERVAL '1 month'));
Создадим таблицу истории статусов транзакций по поставкам:
CREATE TABLE public.tr_history (
dt timestamp without time zone not null,
sku bigint not null,
status bool
)
WITH (
appendonly = true,
orientation = column,
compresstype = zstd,
compresslevel = 1
)
DISTRIBUTED BY (sku, dt)
PARTITION BY RANGE (dt)
(START ('2022-01-01 00:00:00')
END ('2025-01-01 00:00:00')
EVERY (INTERVAL '1 month'));
Для большого объёма данных лучше использовать колоночные таблицы (append‑only — новые данные можно добавлять, но существенные данные нельзя изменить) со сжатием и партиционированием. Логика распределения данных по сегмент‑хостам (дистрибуции) значительно влияет на производительность выборки. Подходы к выбору полей для дистрибуции зависят от сценариев использования.
Для справочных данных создадим три таблицы подобной структуры:
CREATE TABLE public.groups (
groupcode character(32),
groupname character(32),
CONSTRAINT groups_pk PRIMARY KEY (groupcode))
DISTRIBUTED REPLICATED;
Справочники будут небольшие, поэтому размещаем копии на каждом сегменте для оптимизации доступа к ним при выборке фактических данных на каждом сегменте.
Для пакетной заливки данных проще всего использовать команду COPY в psql:
\copy public.sfgw from sfgw.csv HEADER;
Также данные можно загрузить из внешних источников по инструкции.
Этап 3. Заполняем таблицы демонстрационными данными
Для демонстрации загрузим 50+ миллионов записей на ~ 6 ГБ, создадим три справочника с десятками, сотнями и тысячами значений, а также таблицу истории статусов транзакций и занесём в неё 50+ миллионов записей.
Реализуем представление с соединением фактических данных с таблицей статусов транзакций и несколькими справочниками:
CREATE VIEW public.shipping_v AS
SELECT sfgw.groupcode, sfgw.shopcode, sfgw.sku, sfgw.dt, sfgw.qnty, sfgw.weight,
g.groupname, s.shopname, sku.skuname, sku.created_at
FROM public.shipping sfgw
INNER JOIN (SELECT dt,sku FROM public.tr_history – история транзакций
WHERE status) h ON h.dt = sfgw.dt AND h.sku = sfgw.sku
LEFT JOIN public.groups g ON g.groupcode = sfgw.groupcode – справочник групп
LEFT JOIN public.shops s ON s.shopcode = sfgw.shopcode – справочник магазинов
LEFT JOIN public.skus sku ON sku.skucode = sfgw.sku; – справочник наименований позиций
Отмечу, массивно‑параллельная архитектура ориентирована на работу со схемами и соединениями больших фактографических таблиц и множества небольших справочников. В приведённом примере соединяются более 50 миллионов записей. Для таких соединений настраивается дистрибуция. Мы используем INNER JOIN, чтобы хеш‑таблица строилась по таблице с меньшим числом строк. Но лучше объединить данные факта и истории транзакций в одной таблице. Это потребует больше места, но масштабы будут не критичны за счёт сжатия.
Этап 4. Создаём дашборд в DataLens
Переходим в DataLens → Подключения → Новое подключение → Greenplum и создаём подключение. С Managed Service for Greenplum процесс подключения занимает секунды.
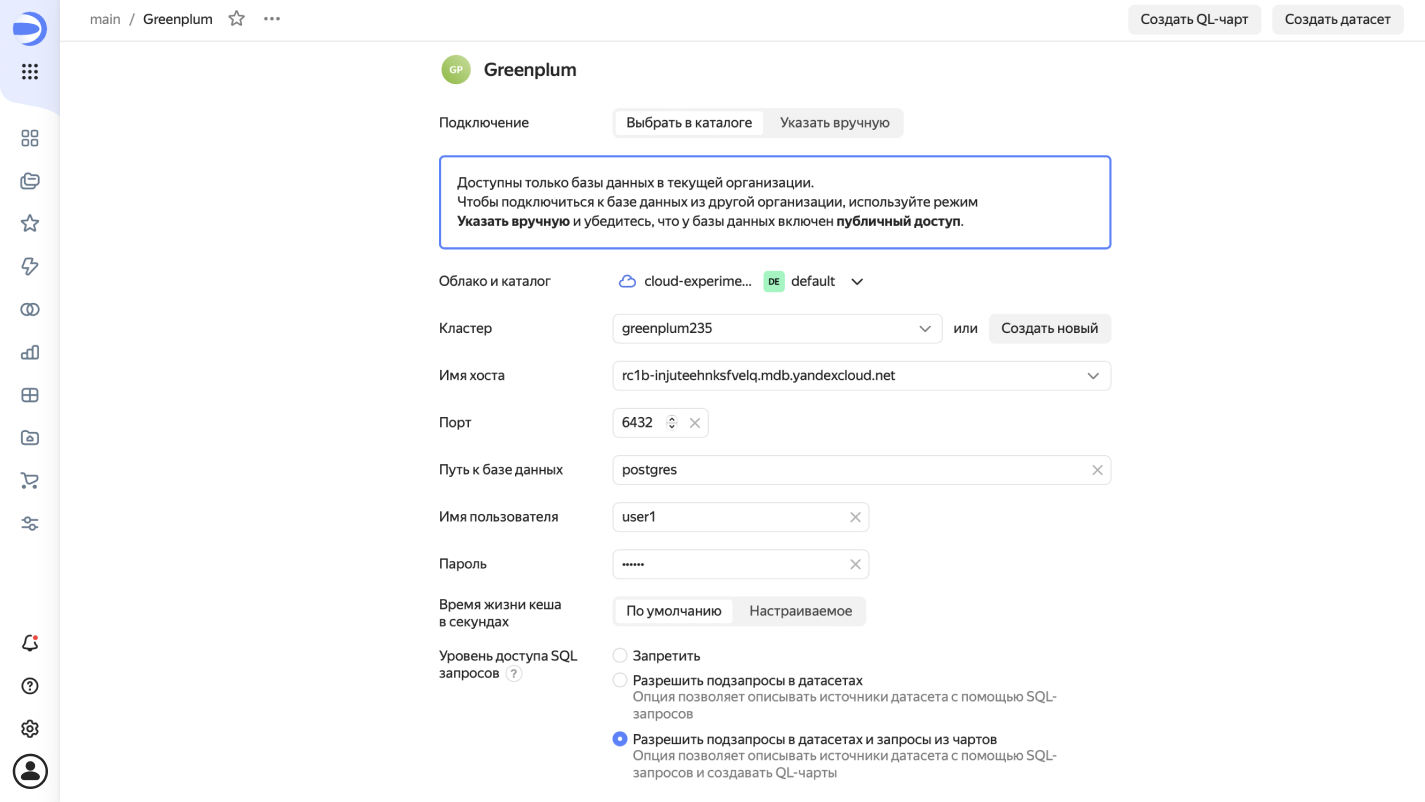
Настраиваем датасет на созданном ранее представлении:
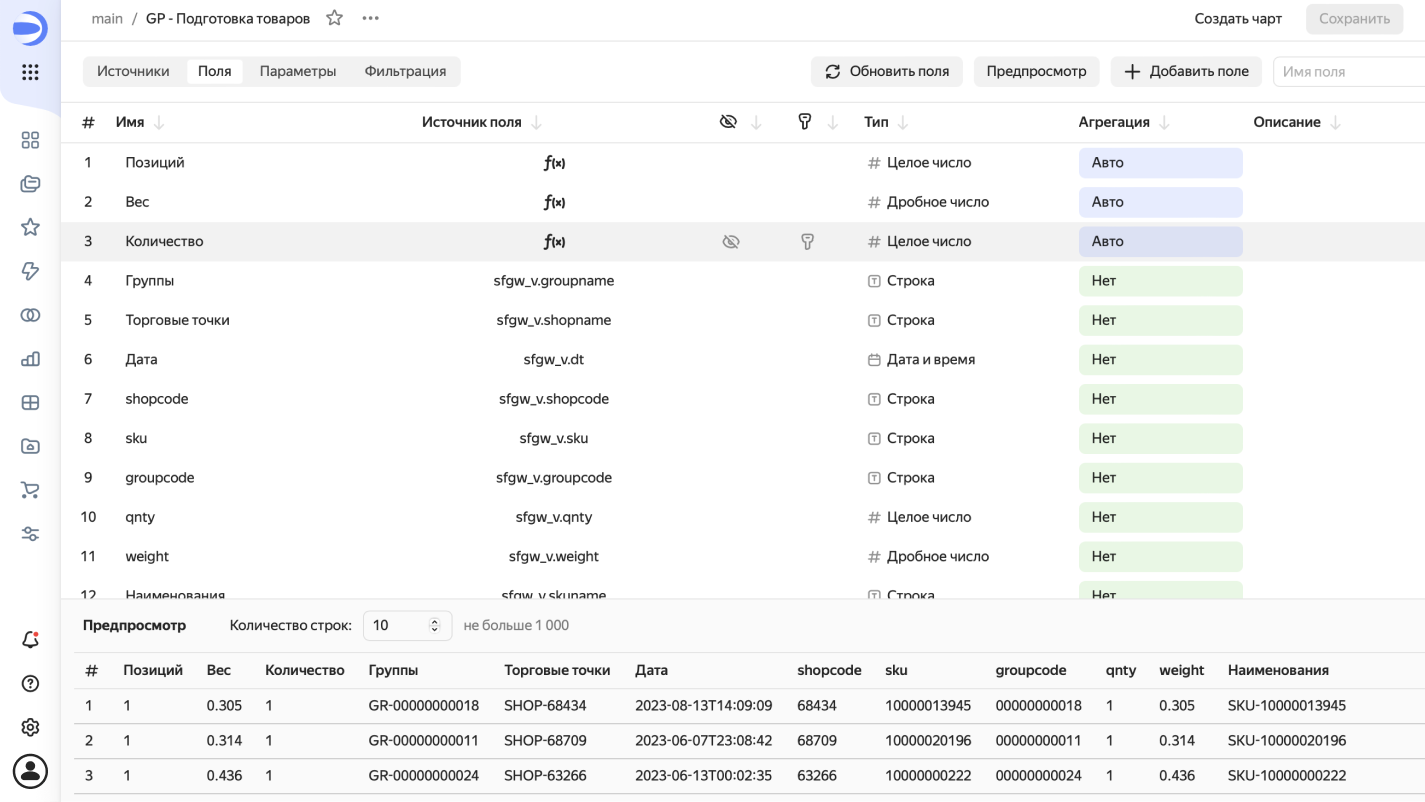
Реализуем за несколько минут чарты:
-
Количество и вес подготовленных товаров по магазинам (топ‑50)
-
Количество наименований по всем магазинам
-
Распределение веса товаров по группам
-
Динамику количества и веса по периодам
-
Индикатор количества наименований
-
Индикатор общего количества операций
Индикаторы создаём на отдельном датасете, который основан на одной таблице фактов. Это позволяет получать результат быстрее, потому что СУБД читает только одну колонку одной таблицы.
Размещаем чарты на дашборде, добавляем селекторы и проверяем, как Greenplum справится с задачей.
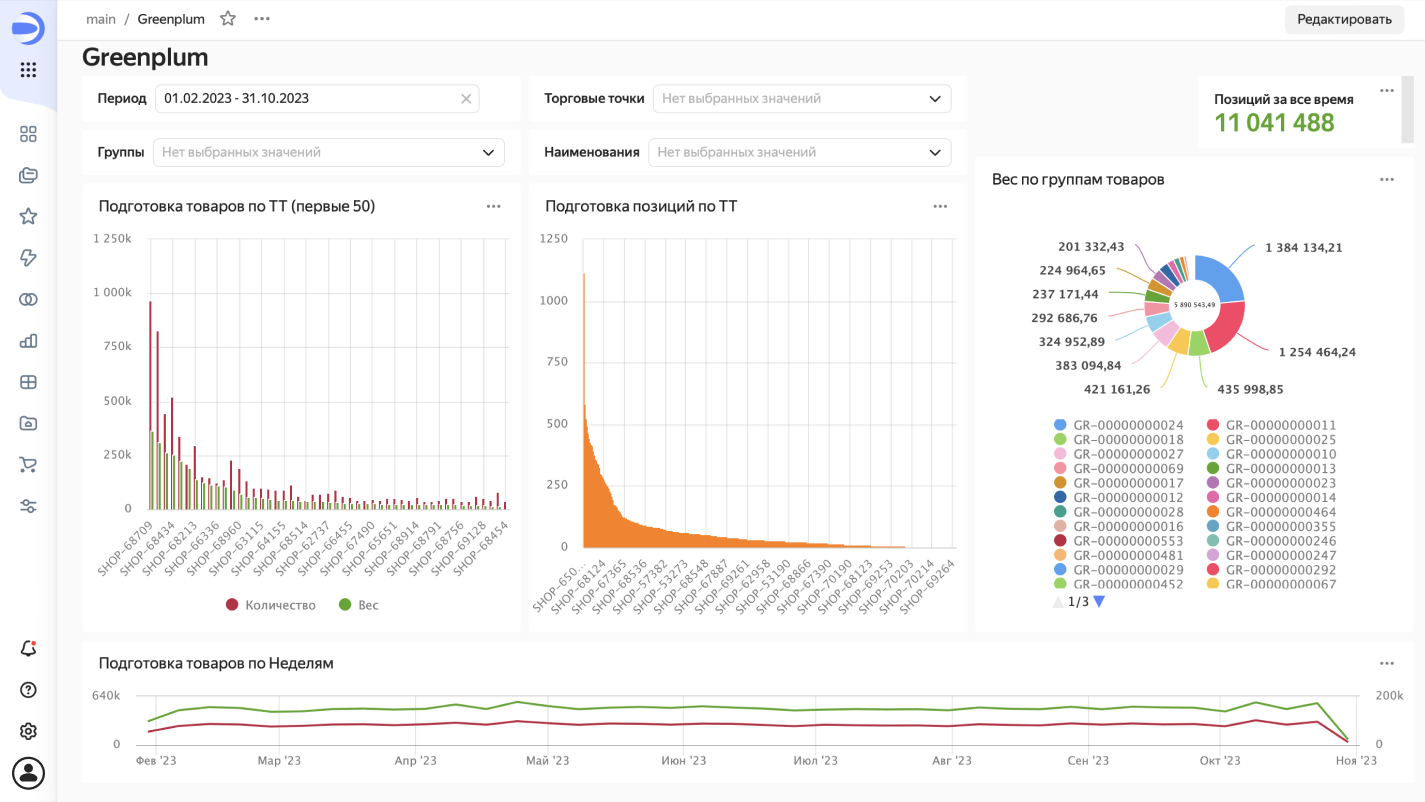
На кластере минимальной конфигурации запросы под 5 чартов и 4 селектора отработали, но попали в лимиты DataLens не без труда, затратив около 30 секунд на график. Проблема в соединении фактографических таблиц с 50+ миллионами строк в каждой. Стоит избегать таких соединений и использовать широкие фактографические таблицы колоночного типа. Также стоит уделить внимание настройкам распределения и партиционирования данных, проанализировать и устранить узкие места конфигурации. Например, при объединении данных в единой таблице фактов, без изменения настроек дистрибуции и партиционирования, запросы отрабатывают уже за ~ 12 секунд. Также таблицы фактов могут объединяться вертикально, что в ряде случаев позволит оптимальнее использовать ресурсы MPP‑системы. И, конечно же, доступен внутренний ETL.
Итак, в нашем примере больше всего усилий мы потратили на подготовку данных и построение витрин, а визуализация в DataLens, как обычно, заняла считанные минуты.
Подведём итоги
Благодаря Managed Service for Greenplum вы можете в самые короткие сроки развернуть и настроить кластер Greenplum и использовать всю его мощь для обработки больших потоков и объёмов данных. И его будет просто связать с DataLens, чтобы визуализировать данные, используя OLAP‑возможности Greenplum.

В этой статье мы расскажем, как: