Распознавание речи с помощью Playground
Чтобы распознать речь из аудиофайла через SpeechKit Playground:
-
В консоли управления выберите каталог, в котором вы будете работать с сервисом.
-
Перейдите в сервис SpeechKit.
-
На панели слева выберите SpeechKit Playground.
-
Перейдите на вкладку Распознавание речи.
-
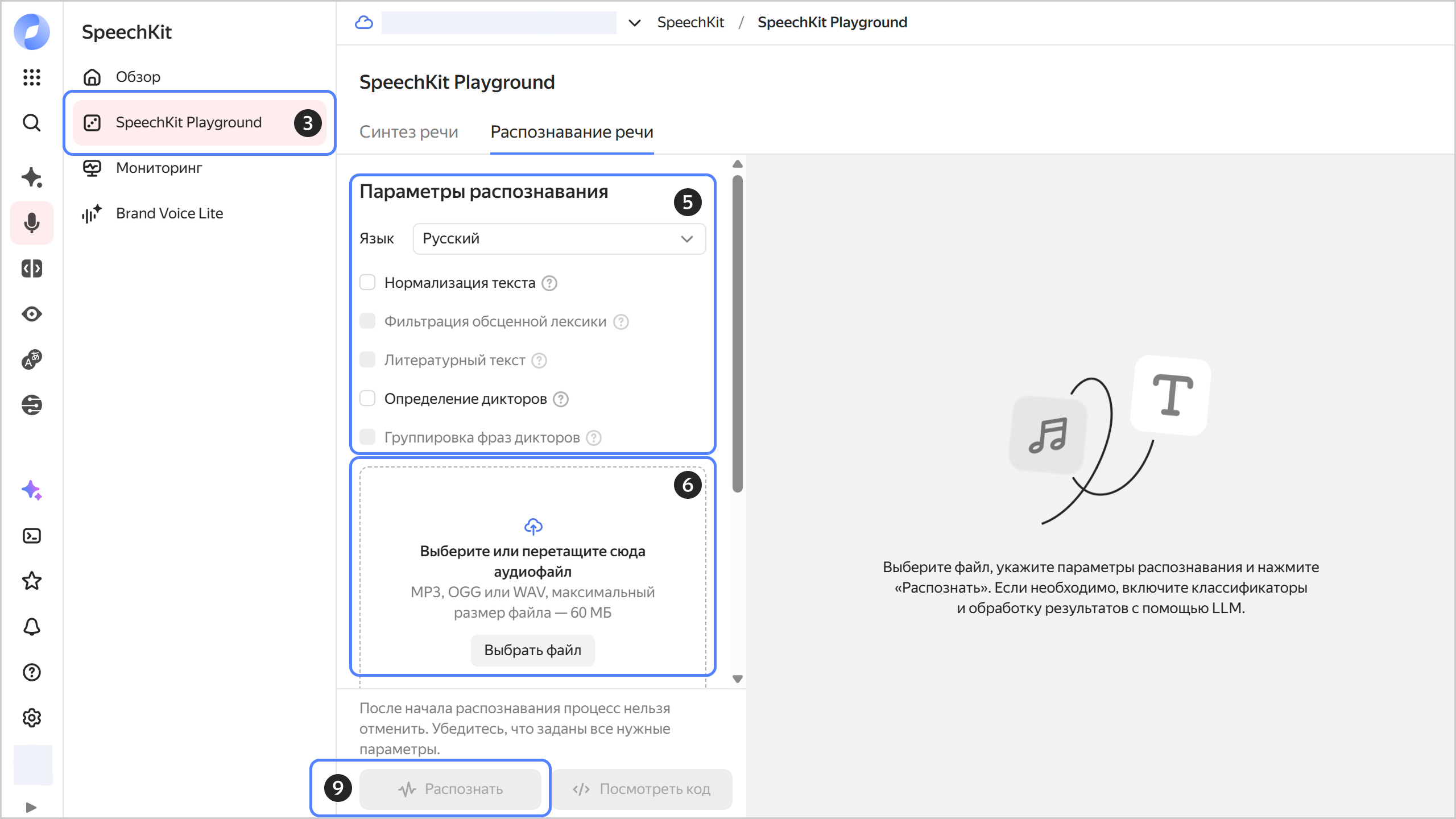
В блоке Параметры распознавания:
- Язык — выберите нужный язык или оставьте значение
Автоматически. - Нормализация текста — представляет даты и время в цифровом формате, преобразовывает числа из словарного в цифровой формат и открывает доступ к дополнительным настройкам.
- Фильтрация обсценной лексики — маскирует обсценную лексику.
- Литературный текст — добавляет заглавные буквы и знаки пунктуации.
- Определение дикторов — размечает, какому из дикторов принадлежит каждая распознанная фраза.
- Группировка фраз дикторов — разделяет фразы на две группы по дикторам.
- Язык — выберите нужный язык или оставьте значение
-
Нажмите Выбрать файл или перетащите аудиофайл в зону загрузки.
Совет
Заранее конвертируйте файл в поддерживаемый аудиоформат: MP3, WAV или OGG с аудиокодеком OPUS. Максимальный размер файла — 60 МБ.
-
Классификаторы — находит в тексте фразы заданной категории, например, приветствие, негатив или мат. Работает только для русского языка.
-
Обработка результатов — обработка результатов с помощью LLM:
- Модель — выберите модель для обработки. Стоимость обработки зависит от выбранной модели.
- Инструкция:
- Напишите промпт в поле ввода или выберите готовый.
- Формат результата — укажите предпочитаемый формат для результатов распознавания.
- Добавить инструкцию — добавьте еще одну инструкцию. Всего можно добавить до пяти инструкций.
-
Нажмите Распознать, чтобы распознать речь в аудиофайле.
Распознавание может занять от нескольких секунд до нескольких минут в зависимости от размера аудиофайла.
-
Нажмите Посмотреть код, чтобы получить код запроса для Python REST или Python gRPC.
SpeechKit Playground предоставляет базовые возможности распознавания речи. Более гибкие настройки распознавания доступны только через API.