Как правильно работать с S3‑хранилищем, чтобы увеличить его производительность
Расскажем, что позволит увеличить производительность объектного хранилища и обеспечить быстрый доступ к вашим данным.
3 июня 2024 г.
10 минут чтения
Объектное S3-хранилище зачастую выбирают для работы с большими объёмами разнородных данных. Но зачастую пользователи сталкиваются со сложностями, которые снижают производительность хранилища и увеличивают затраты на инфраструктуру. Объясняем, как избежать типичных проблем и получить доступ ко всем возможностям S3.
Что такое S3-хранилище и кому оно подойдёт
S3 — это вариант «плоского» (не иерархического) объектного хранилища. С точки зрения такой системы все объекты равнозначны. Именно поэтому S3-хранилища хорошо подходят для долгого хранения разнообразной информации, к которой бывает нужно быстро получить доступ. Они позволяют работать с неограниченными объёмами данных, автоматически масштабироваться и запускать большое количество приложений одновременно.
Задачи, которые решают пользователи с Yandex Object Storage — универсальным масштабируемым хранилищем, совместимым с Amazon S3 API:
Компания GetCourse хранит петабайты видеокурсов и обеспечивает своевременный доступ к ним для тысяч пользователей.
Sports.ru строит гибридную инфраструктуру: размещает в S3-хранилище тексты и фотографии, чтобы ускорить доставку информации пользователям.
«Альфа Капитал» ведёт электронные архивы: хранит документы, которые должны быть молниеносно доступны всем сервисам компании и размещает документы, которые помогают новым клиентам подключиться к нужным продуктам.
Несмотря на все преимущества, неправильная работа с S3-хранилищем может ощутимо понизить производительность информационных систем, а также привести к увеличению финансовых затрат.
Что мы понимаем под производительностью в контексте работы с S3?
Производительность системы хранения данных (СХД) — это количество операций ввода или вывода, которые может обработать СХД за единицу времени. Её можно было бы оценить с помощью двух базовых параметров:
IOPS или RPS. IOPS — количество операций ввода или вывода, которые СХД выполняет за одну секунду; RPS — количество запросов в секунду. Эти параметры зависят от задержки выполнения запросов и параллельности нагрузки.
Throughput — пропускная способность канала, которая зависит от ширины самого канала и шины, через которую передаются данные.
Ещё один способ оценки — измерить производительность дисков (HDD, SSD), на которых построено хранилище: пропускная способность и эффективность работы СХД зависят от них напрямую. Чтобы измерить производительность локальной СХД, можно использовать утилиты fio и другие готовые решения.
Но не обладая информацией, откуда приходят запросы, как их создают и какой путь они проходят, сложно точно оценить производительность нелокального хранилища (такого как S3) и понять, от чего именно она зависит.
В случае, когда приложение делает запрос не в локальное хранилище, а в S3, производительность оценивается как время, за которое запрос преодолеет путь от приложения до S3 и обратно. При этом запрос преодолевает множество этапов.
Предлагаем пошагово проследить путь, который проходят запросы пользователя к объектному хранилищу, и выяснить, что происходит на каждом из его этапов:
Отправка запроса.
Выход запроса в сеть.
Балансировка запроса.
Получение запроса S3-хранилищем.
Проверка прав доступа.
Запись объекта в хранилище.
Возвращение ответа.
Для каждого этапа обсудим факторы, влияющие на скорость запроса и работу хранилища, и сформулируем практические советы, которые помогут увеличить производительность.
1. Отправка запроса к данным
Этот этап полностью контролирует пользователь.
Какие сложности могут повлиять на производительность
Эффективность запроса на этом этапе лежит на плечах клиента (например, на администраторе его системы) и влияет на общий результат работы с S3. Популярные проблемы:
Нехватка ресурсов CPU.
Недостаточная производительность дисковой подсистемы, которая хранит информацию на компьютере и поставляет данные для теста.
Как их исправить
Убедитесь, что приложению, работающему с S3, достаточно ресурсов: CPU, RAM, disk IO.
С точки зрения CPU и памяти:
В OS, где запущен тест, достаточно ядер CPU, и они не загружены другими приложениями. Если тестирование проводится внутри виртуальной машины, то лучше добавить ядра vCPU, чтобы исключить возможные проблемы на этой стадии. Для полноценного многопотчного тестирования желательно иметь не менее 8 vCPU.
Ядра, выделенные под машину с тестом, не разделяются с другими виртуальными машинами. Это поможет предотвратить возможное влияние соседних виртуальных машин на работу теста.
Запуск теста не осуществляется на прерываемых машинах, это является ещё одной частой проблемой. Если нагрузка запускается внутри контейнера K8s, то убедитесь, что выделено 100% CPU.
Также важно обращать внимание не только на гостевую ОС (чтобы не было других потребителей CPU), но и вовне (чтобы сама виртуальная машина не останавливалась, не подтормаживала).
К тому же важна производительность локальной дисковой подсистемы, откуда берутся данные для передачи в S3-хранилище. В случае недостаточной производительности дисковой подсистемы результаты работы с S3 будут ниже, так как значительное время уйдёт на получение данных до формирования запроса к S3. Убедитесь, что локальный диск, где размещены тестовые данные, значительно быстрее, чем ожидаемая скорость S3. Используйте High IOPS SSD (быстрые сетевые диски) или RAM-диски (для данных в оперативной памяти), чтобы хранить данные для теста, или считывайте их в оперативную память до того как будете выполнять замер производительности S3. Например, если вы загружаете данные с HDD в S3, а S3 отрабатывает любые запросы мгновенно, общий показатель результата теста будет не выше производительности HDD (100 RPS, 100 МБ/c).
2. Выход запроса в сеть
После того, как приложение отправляет запрос в хранилище, он попадает в сеть.
Какие сложности могут повлиять на производительность
Низкая пропускная способность канала.
Загруженность канала другим трафиком.
Ограничение скорости канала.
Как их исправить
Здесь сработают те же рекомендации, что и для предыдущего раздела. А если точнее — надо исключить загрузку канала другими приложениями и трафиком, выделив больше ресурсов.
Кроме того, могут помочь ещё несколько советов:
Проверьте пропускную способность вашей локальный сети с помощью утилиты iperf.
Проверьте тип сетевого интерфейса: если у сетевого соединения низкая скорость, закономерно, что данные будут выходить в сеть долго. Речь не об ограничении пропускной способности полосы, а именно о latency узкого канала при передаче данных: 10 МБ данных пройдут быстрее через 10-гигабитную сеть, чем через 1-гигабитную сеть несмотря на то, что в обоих случаях не упрутся в предельно допустимую ширину канала.
Минимизируйте влияние «дикого» интернета. Каналы выхода в интернет бывают разные, но все они влияют на производительность. Чтобы снизить воздействие этого фактора, проведите тесты работ с S3 на виртуальных машинах, которые находятся внутри Yandex Cloud, и проверьте загрузку канала сторонним трафиком.
Ускорьте выход запроса, создав приватные выделенные сетевые соединения между локальной и облачной инфраструктурами. Сервис Interconnect, разработанный Yandex Cloud, позволяет создавать приватные соединения поверх магистрального канала. При этом пропускная способность выше, а задержки меньше, по сравнению с подключением через интернет.
3. Балансировка запроса
После того как запрос вышел в сеть, он приходит из магистральной сети в одну из точек обмена трафиком и попадает в ближайший балансировщик трафика, где распределяется в одну из зон доступности, обеспечивая отказоустойчивость. С этого момента ответственность за прохождение запроса и его скорость лежит на Yandex Cloud.
Несмотря на то, что домен storage.yandexcloud.net имеет один IP-адрес, трафик обрабатывается большой фермой балансировки трафика, которая состоит из множества серверов в разных локациях. Задача балансировщика — передать запрос в ближайшую зону доступности S3-сервиса. Если одна из зон доступности не ответит, трафик перераспределится между другими зонами автоматически, и S3 продолжит работать.
4. Получение запроса S3-хранилищем
Запрос поступает на nginx (прокси-сервер), и предаётся в компонент S3-proxy, который отвечает за разбор запросов протокола AWS S3. Важно, что прежде чем хранилище получит запрос, он должен полностью поступить на nginx.
Какие сложности могут повлиять на производительность
Если устанавливать отдельное соединение с S3 на каждый запрос, то будут возникать множественные TLS-сессии.
Для реализации множества операций с S3 пользователь может многократно вызывать команды, взаимодействующие с ОС (CLI-команды). При этом клиент и сервер обмениваются серией сообщений (TLS-handshake). Каждая серия состоит из нескольких этапов, поэтому весь процесс занимает значительное время, особенно если у сети высокая задержка.
Как их исправить
Чтобы избежать множественных TLS-сессий, можно посылать несколько HTTP-запросов внутри одного соединения TLS, используя keepalive-опцию S3-клиента. Если требуется скопировать несколько мелких объектов, эта оптимизация позволяет вдвое ускорить получение запроса хранилищем.
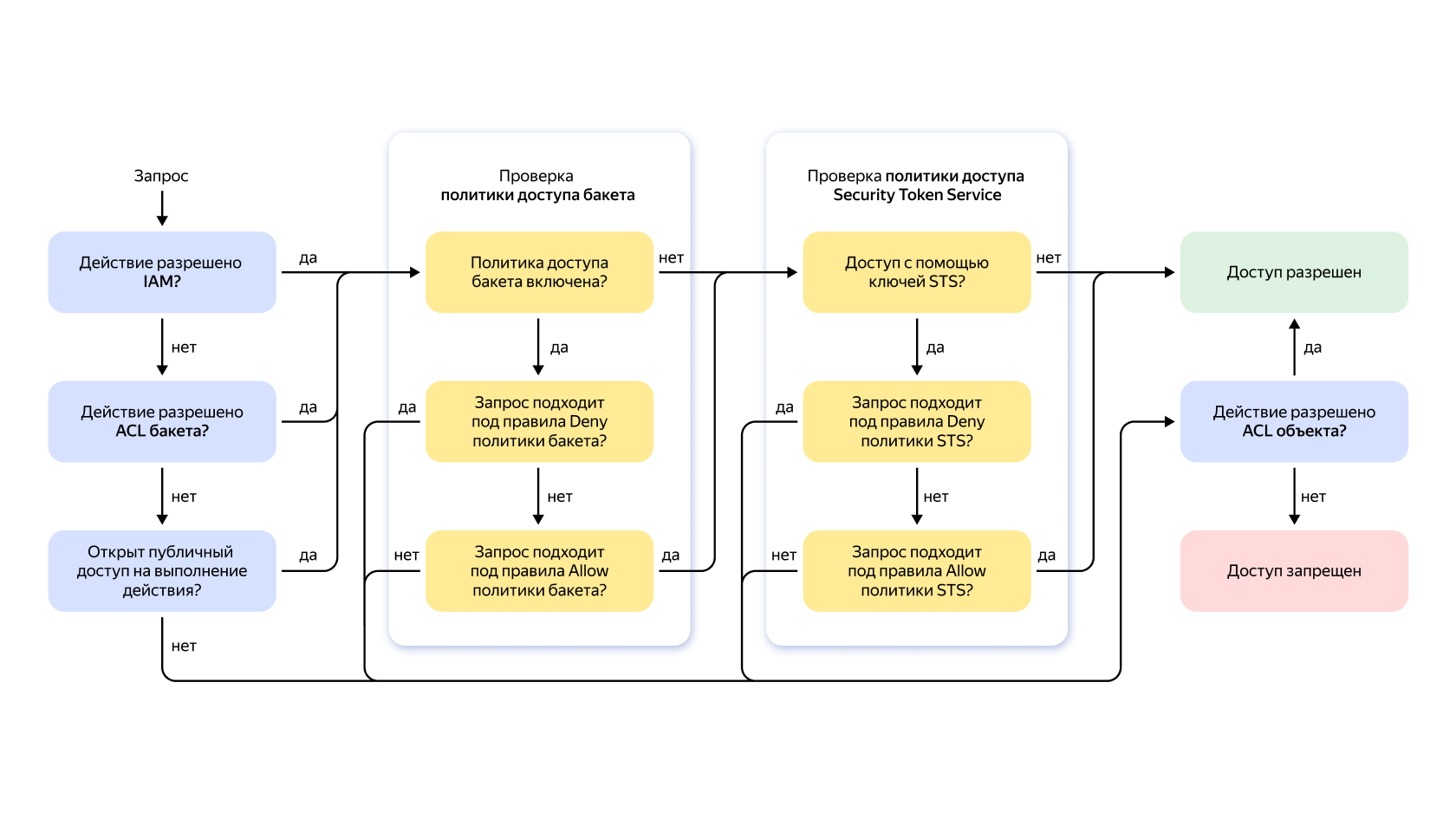
5. Проверка прав доступа S3
Yandex Object Storage — это многопользовательская система хранения, совместимая с S3 API, которая имеет многоуровневую систему управления правами доступа.
Подробнее о механизмах управления доступом мы писали в документации.
6. Запись объекта в хранилище
Yandex Object Storage обеспечивает запись и хранение данных в трёх репликах, а каждую из них размещает в своей географически удалённой зоне доступности. Сервис обеспечивает строгую согласованность данных: мы сохраняем данные в трёх зонах доступности и только после размещения на физических носителях возвращаем клиенту ответ об успешности операции.
Хотя эта функциональность — необязательный пункт стандарта S3-хранилища, согласованность данных позволят клиентам эффективно реализовывать сценарии синхронизации данных: работать с единым хранилищем из нескольких зон доступности и всегда получать единый стейт данных.
Синхронная запись в три зоны доступности требует времени. Вот пример стандартного времени, которое требуется для сохранения данных в нашем объектном хранилище от момента, когда nginx proxy полностью получил запрос от клиента и провёл проверку авторизации, до ответа клиенту.
Размер объекта
Медианное время
Комментарий
0 КБ
15 мс
Создание объекта. Запись об объекте и его метаданные будут храниться в трёх зонах доступности, поэтому даже на создание пустого объекта уходит время на синхронный коммит в PosrgreSQL.
4 КБ
24 мс
Создание объекта и запись его данных на диски в трёх зонах доступности.
512 КБ
50 мс
Создание объекта и запись его данных на диски в трёх зонах доступности.
50 МБ
1.2–1.5 с
Большие объекты занимают больше времени из-за передачи и записи данных на диски.
При размещении и хранении данных в одной зоне доступности этот процесс был бы быстрее, но хранение было бы менее надёжным, на что сервис Yandex Cloud пойти не готов, так как обеспечение высокого уровеня надёжности хранения пользовательских данных является для нас приоритетным.
7. Возвращение ответа
Последний этап — обратный путь от S3-proxy до приложения через интернет.
Какие сложности могут повлиять на производительность
У зон доступности Yandex Cloud есть выходы в магистральные каналы связи с очень широкими каналами. Они быстро передают ответ в интернет, однако со стороны клиента могут возникнуть сложности при приёме обратных запросов. Возможные причины этих сложностей для первых двух этапов мы описали выше: отправка запроса к данным и выход запроса в сеть.
Мы придерживается принципа выделения ресурсов в единоличное пользование везде, где это только возможно. Объектное хранилище Yandex Object Storage старается выполнить все поступающие запросы от приложений клиентов. Например, если один из клиентов загружает данные со скоростью свыше 10 гигабайт в секунду (~100 Gbit/s), мы выдержим эту нагрузку, не нарушив SLA других клиентов Yandex Cloud.
Выводы
Итак, мы прошлись по основным этапам пути запроса от клиента. Выяснили, как избежать снижения скорости работы с S3-хранилищем:
Выделять необходимые ресурсы CPU/RAM и сети на стороне клиента.
Минимизировать влияние сети и сетевых задержек в интернете.
Отслеживать скорость дисковой подсистемы с данными для загрузки в S3.
Использовать keepalive для избежания пересоздания TLS-сессий.
Также разобрали этапы прохождения запроса через компоненты S3 на стороне Yandex Cloud, чтобы обеспечить быструю обработку запросов и надёжность хранения данных.
Сервис Yandex Object Storage — это многопользовательская система хранения с многоуровневым управлением правами доступа. Сервис поддерживает API AWS S3, что позволяет использовать не только встроенные возможности Yandex Cloud, но и большинство популярных инструментов, совместимых с AWS S3: файловые браузеры, консольные клиенты, SDK и другие.
Yandex Object Storage содержит все преимущества облачного S3-хранилища и позволяет хранить объекты произвольного формата размером в несколько терабайт. Все данные защищены в соответствии с Федеральным законом Российской Федерации «О персональных данных» № 152-ФЗ.