Привилегии суперпользователя в управляемых базах данных чаще всего отключены, но мы сделали альтернативу — роль mdb_admin. Пользователь с такими привилегиями имеет почти те же права, как и суперпользователь, но без возможности «всё сломать».

Greenplum в облаке: про новое в управлении, резервном копировании и трансфере данных
Летом 2021 года мы выпустили новый управляемый сервис Yandex Managed Service for Greenplum® в стадии Preview, а уже 14 марта 2022 года он перешёл в общий доступ (GA). Сегодня расскажем о том, что мы сделали за последние 10-11 месяцев для Greenplum.
14 сентября 2022 г.
15 минут чтения
Greenplum — аналитическая колоночная массивно‑параллельная СУБД, разработанная для хранения и обработки больших объёмов информации. Она позволяет работать с терабайтами и даже петабайтами данных. Традиционно Greenplum разворачивают on‑premise, при этом задачи по установке, обслуживанию и обеспечению ресурсов для масштабирования лежат на владельце инфраструктуры. Мы предоставляем полностью управляемую СУБД, которая позволяет создавать кластеры в облаке всего за несколько минут, и при этом большая часть работы по обслуживанию базы данных лежит на стороне облачной платформы.
Наша страсть к доработкам продуктов open source не только позволила портировать в облако заточенную под локальную установку СУБД, но и продолжить её улучшать. Так как Greenplum основана на PostgreSQL, в разработке которой мы активно участвуем, оптимизация нового сервиса также ведётся непрерывно. Про наш вклад в базы данных open source можно прочитать тут.
Как жить без суперпользователя
Суперпользователь (superuser) в Greenplum, так же как и в PostgreSQL, имеет полный доступ к операционной системе, что является недопустимым для управляемого сервиса в облаке. Управляемый Greenplum имеет обвязки (Control Plane), которые автоматически соединяются с базой данных, создают резервные копии, устанавливают обновления, осуществляют мониторинг и выполняют другие служебные функции. Атака суперпользователя на Control Plane может разрушить кластер или привести к выходу из строя базы данных.
Аналогичное решение по созданию альтернативной роли используют в managed PostgreSQL, но там все возможности суперпользователя разделили на несколько отдельных ролей, например pg_manage_host_resource_settings, pg_manage_vacuum_settings, pg_manage_logging_settings, pg_manage_replication_settings и других.
В нашем Managed Service for Greenplum все они доступны в одной роли mdb_admin. Более того, мы дали возможность mdb_admin управлять владельцами данных (ownership) на уровне суперпользователя, а другим непривилегированным пользователям — создавать собственные расширения (trusted extensions) для Greenplum.
Улучшаем резервное копирование
Ключевые требования к хорошим бэкапам: надёжность, экономичность и быстрое восстановление. Администратору баз данных необходим максимально простой и удобный инструмент. Он должен использовать для копий стандартное хранилище, например объектное, не тратить много ресурсов и не мешать работе базы.
Стандартное решение gpbackup — обкатанное и надёжное, но не одинаково хорошо работает со всеми объектными хранилищами. Также оно делает логические резервные копии, а значит в процессе работы блокирует DDL‑изменения, не эффективно использует ресурсы и не умеет Point‑in‑Time‑Recovery (PITR).
Использовать для создания резервных копий Greenplum в облаке аналогичное решение, которое мы используем для PostgreSQL, невозможно. Для каждого сегмента Greenplum нельзя сделать отдельное PITR, потому что PostgreSQL плохо работает с неконсистентными данными. Если в системе допустить дрифт времени восстановления между сегментами, может оказаться, что транзакции или таблицы частично присутствуют или отсутствуют на разных сегментах. Такого допустить нельзя. Для Greenplum 7 ведётся работа по созданию технологии консистентной точки восстановления, а мы перенесли её в нашу шестую версию и проверили её работоспособность.
Наше решение для резервного копирования баз данных WAL‑G позволяет загружать бэкапы в S3, GCS, Azure или другие облака. Изначально мы разработали его для PostgreSQL, но сейчас поддерживаются MySQL, MongoDB, Redis.
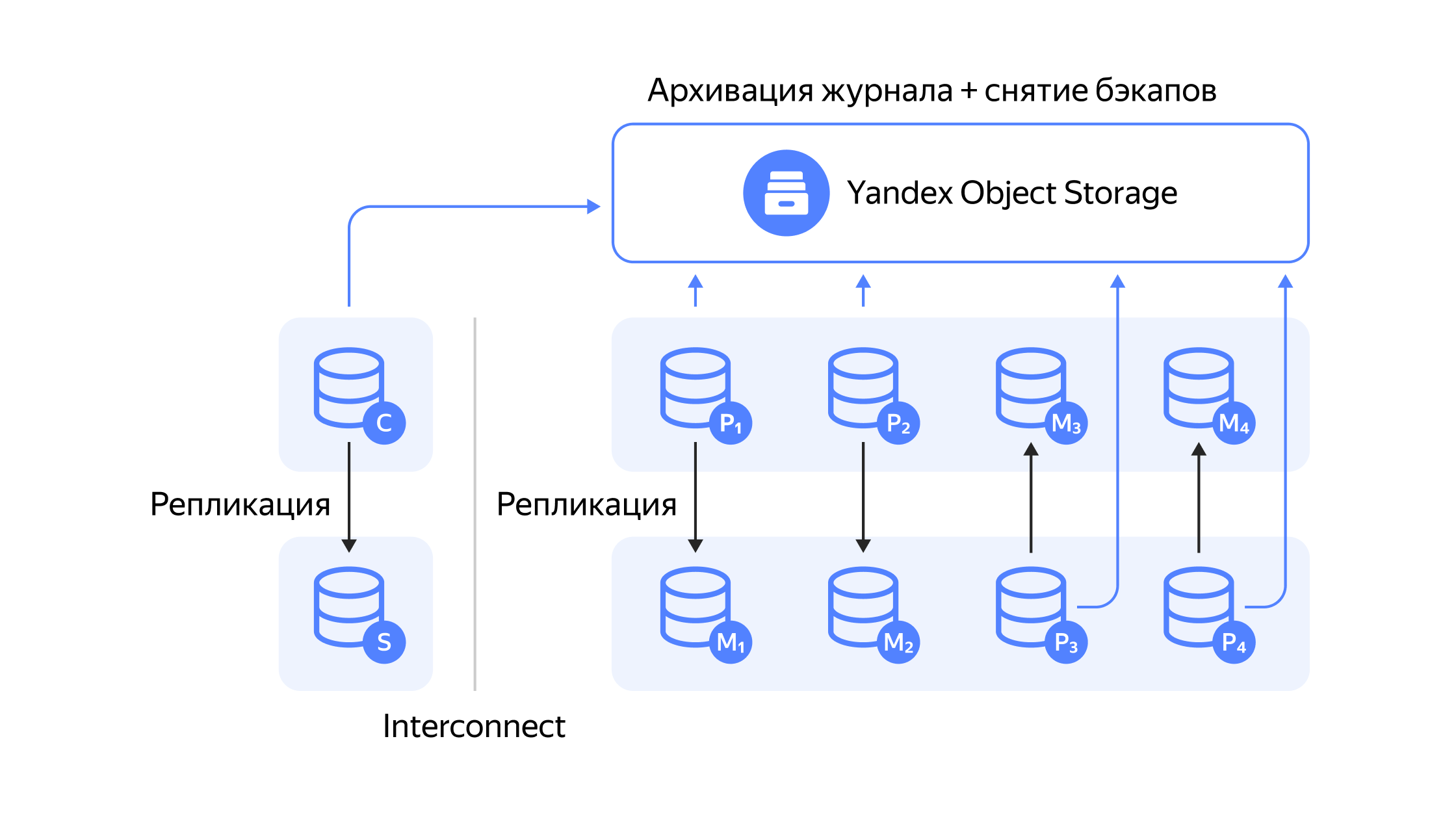
Топология кластера Greenplum в облаке. C — coordinator (координатор), S — standby coordinator (горячий резерв координатора), M — segment mirror (зеркало сегмента), P — segment primary (основной узел сегмента)
Архитектура решения WAL‑G для Greenplum схожа с PostgreSQL. За работу кластера отвечает coordinator и его standby, а также четыре сегмента и их реплики. WAL‑сегменты архивируются в Yandex Object Storage, но, в отличие от PostgreSQL, мы снимаем резервные копии с мастеров, а не реплик.
Актуальную версию WAL‑G для Greenplum можно скачать по ссылке.
Добавляем объектное хранилище
Мы не остановились в развитии нашей системы резервного копирования — следующим этапом стала реализация дельта‑бэкапов. С их помощью сегменты append optimized‑таблиц можно будет не только хранить в одном бэкапе, но переиспользовать в других. Также эти сегменты в любой момент можно будет легко удалить с дисковой квоты (быстрые SSD‑диски), перенеся данные в объектное хранилище, а когда они снова потребуются Greenplum, автоматически вернуть обратно. Таким образом можно сократить затраты, размещая на дорогих дисках только горячие данные.
Сейчас мы работаем над тем, чтобы дать пользователю больше точек восстановления не только на время после бэкапа, но и на другие периоды с частотой в несколько десятков минут.
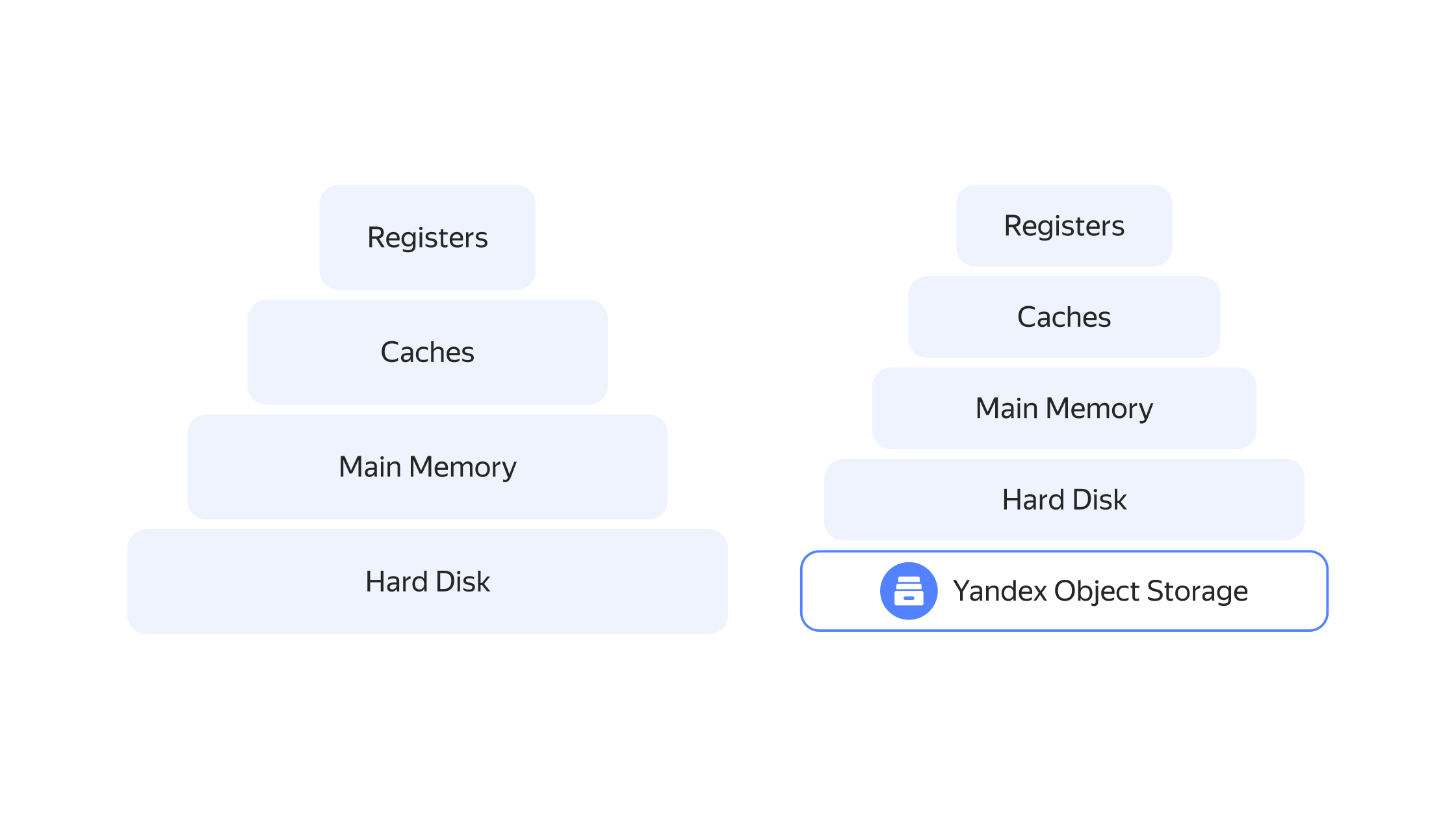
Объектное хранилище существенно дешевле, чем быстрые диски внутри виртуальной машины
Реализация этих возможностей позволит осуществлять быстрое перешардирование — горизонтальное масштабирование с использованием объектного хранилища S3. Когда производительности базы данных станет недостаточно, необходимо будет купить дополнительные виртуальные машины и создать новые сегменты Greenplum. Сразу переносить на них все данные append optimized‑таблиц не нужно, они подтянутся из хранилища автоматически по мере поступления запросов от пользователей.
Таким образом, в будущем наша технология резервного копирования будет не только выполнять свою основную задачу, но и позволит сделать кластеры Greenplum эластичными. Пользователи смогут оперативно нарастить производительность кластера под определённую задачу. Например, если требуется выполнить аналитику большого объёма данных, то необходимо:
-
Создать одну или несколько дополнительных виртуальных машин под новые сегменты.
-
Подключить их к кластеру с доступом в Object Storage и выполнить быстрое перешардирование через S3.
Когда задача будет выполнена, данные остаются в «холодном» объектном хранилище, а лишние машины из кластера удаляются.
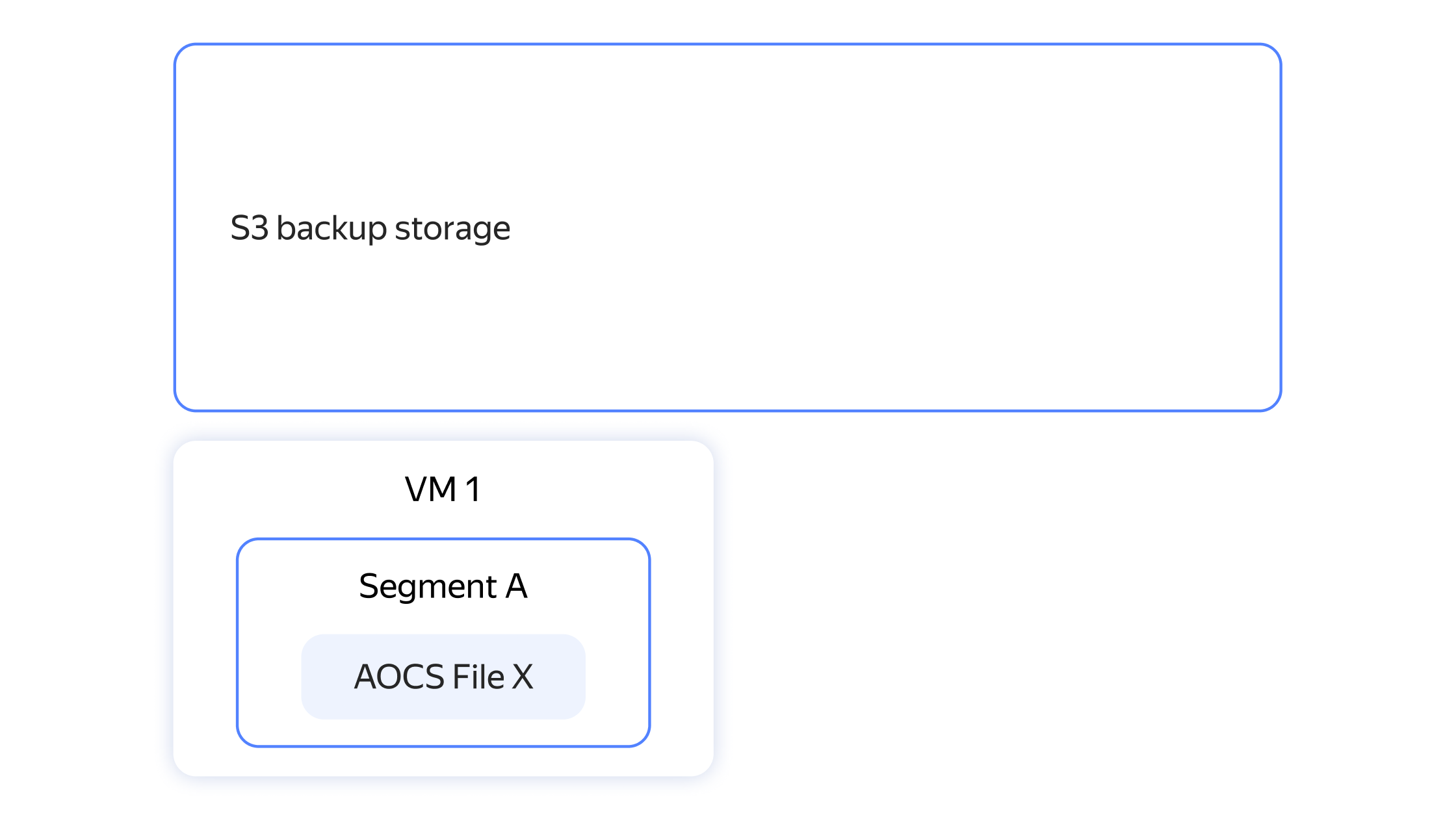
Если все данные доступны в S3, то появляется возможность осуществить быстрое перешадирование кластера. Это позволит не только масштабируемо и эффективно хранить большие объём данных, но и быстро масштабировать потребляемые ресурсы
Всё, что мы разрабатываем для Greenplum, доступно на GitHub, каждый может самостоятельно собрать свой кластер и пользоваться им совершенно свободно в локальной инфраструктуре или облаке. Но большая часть доработок уже готова и доступна в Yandex Cloud и не требует дополнительных трудозатрат.
Создаём инструменты для трансфера данных
Инструменты Data Transfer помогают выполнить миграцию данных между базами данных или хранилищами. Мы разработали трансферы трёх типов:
-
Greenplum — Greenplum. Применяется, когда необходимо выполнить миграцию данных из локального Greenplum на железе или другого облака в Yandex Cloud. Данные переносятся в режиме снапшота.
-
Другие БД — Greenplum. Применяется, когда необходимо перенести в Yandex Managed Service for Greenplum® данные из других баз данных (PostgreSQL, MySQL и т. д.) или очередей (Kafka и т. д.). В Greenplum создаётся общее хранилище, куда загружаются данные разных систем. Трансфер возможен как в режиме снапшота, так и в режиме репликации, если необходим постоянный приём свежих данных.
-
Greenplum — ClickHouse. В Greenplum готовится агрегат, который выгружается в ClickHouse для создания в нём витрины данных и подключения, например DataLens. Данные переносятся в режиме снапшота.
Для осуществления трансфера мы не используем стандартные инструменты, а разработали свои. Подключение к Greenplum осуществляется напрямую к сегментам кластера, чтобы иметь возможность импорта и экспорта больших данных с технологией параллельной записи и чтения. Больше о вариантах трансфера данных читайте в нашей документации.
Делаем Greenplum лучше и стабильнее
За последний год мы исправили больше 12 багов Greenplum. Например, была найдена опечатка в DeserializeResGroupInfo (), где len использовалась вместо cpuset_len, что в большинстве случаев приводило к копированию мусора, а иногда и к сбою всего кластера.
Также мы сделали патч для перезагрузки SSL‑сертификата без перезагрузки самого сервера базы данных.
Полный список сделанных нами изменений можно посмотреть тут, тут и тут. Команда платформы данных каждый день работает над улучшением сервиса. Попробуйте построить хранилище данных на Greenplum прямо сейчас.
