Preparing and uploading data for Brand Voice Self Service
With Brand Voice Self Service, you can create a unique voice based on recorded audio. You can use this voice for speech synthesis based on plain text or pattern-based synthesis with variables. SpeechKit supports voices for Russian and Kazakh. If you want to create a voice for a different language, contact us for details.
Note
It takes up to one month to prepare a Brand Voice Self Service model using the uploaded data.
What data is required for training
To create your own Brand Voice Self Service voice, you need to prepare and upload the training data: audio recordings and the texts they are based on. The amount of data needed to train the model depends on how you intend to use the voice and the speaker's manner of speech. For example, a voice used to narrate literary fiction would require more data than a voice for a virtual assistant. Send us voice audio samples without music or post-processing to receive specific recording recommendations and data volume requirements.
The training data is uploaded in two files:
- ZIP archive of audio recordings in WAV format.
- UTF-8 encoded TSV table with the transcripts of recordings from the archive. The table should have two columns:
- Name of the audio file with the speaker's text.
- Line with a verbatim transcript of the recording. If the text describes a template with a variable, the variable part must be in
{variable_name = variable_value}format.
We recommend uploading data in batches after each studio recording. If for any reason that is not possible, you can upload all your recordings in one archive along with the corresponding table of transcripts. The format of the provided data remains unchanged.
Warning
Each recording should contain a full phrase of one or several sentences. A recording cannot be longer than 15 seconds. The transcripts in the table must exactly match the text in the audio.
Each audio recording should start and end with silence, and any clipped sounds or words are not acceptable. You must not use a podcast recording cut into 15-second segments; doing so will split words and phrases, and the recordings will not match phrase boundaries. It is not possible to train a quality model on such data.
A correct audio recording should be as follows: there are a few milliseconds of silence at the beginning and end of the audio, and the phrase is complete.
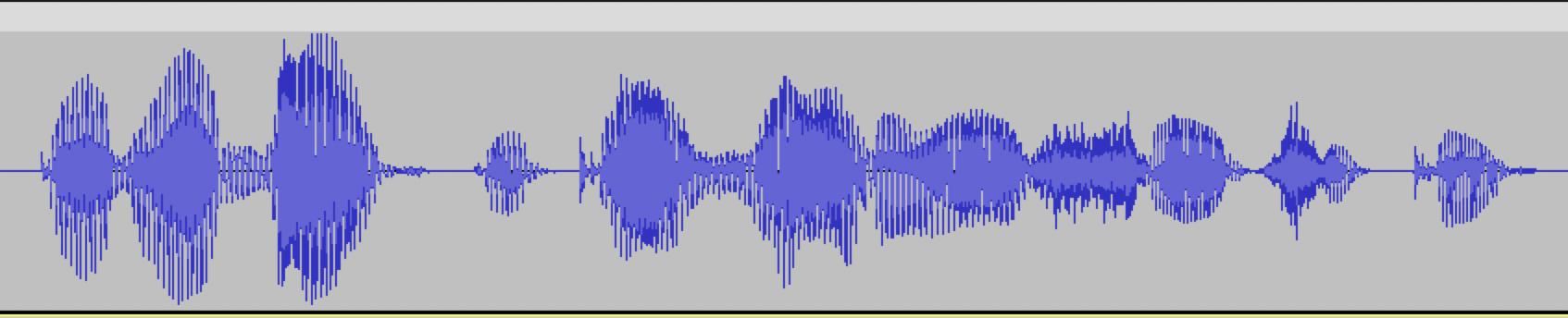
A poor audio recording would be as follows: there are no silence intervals at the beginning and end of the audio, and the start and end of the phrase are cut off.
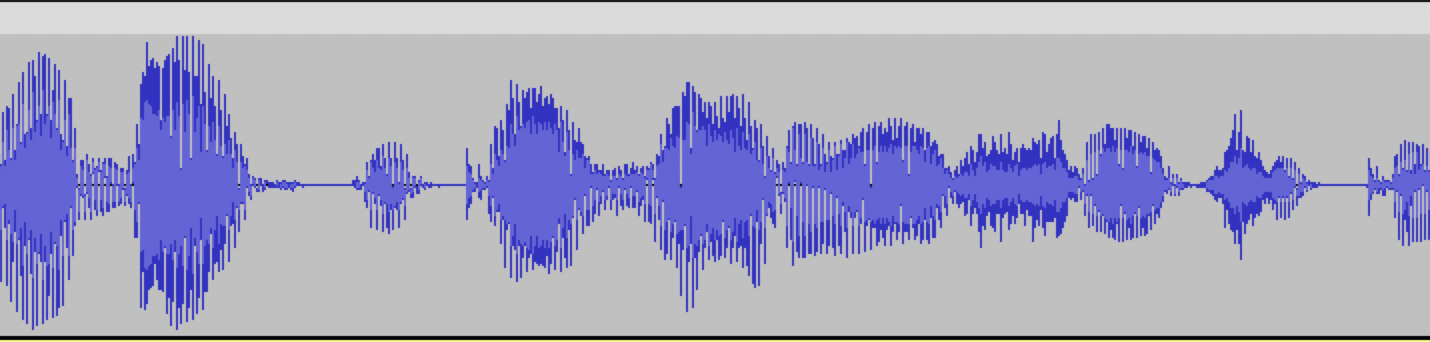
Such audio recordings will have distortions and are not suitable for model training.
Example of prepared data
-
Recordings.zip archive containing the files 1.wav, 2.wav, 3.wav.
-
Table in TSV format, matching the audio files with their transcripts:
The table header is given as an example, it must be excluded from the uploaded file.
recordings text 1.wav Books are a uniquely portable magic. 2.wav We have an amazing book for you! 3.wav This book is suitable for children from the age of five.
Prepare data
Brand Voice Self Service allows you to synthesize an arbitrary text (full-text synthesis) as well as a phrase based on a pre-recorded pattern (pattern-based synthesis). In pattern-based synthesis, apart from the text itself, you need to provide an audio file that SpeechKit will use to copy speech intonations from.
For your voice to work for both synthesis modes, we recommend that you do the following:
- First, record your audios and their transcripts for full-text synthesis: 1.wav We are checking your order.
- To enable pattern-based synthesis, you will also need to make additional recordings and upload the matching texts with marked up variables: 1.wav Hi, {agent_name=Anastasia}! We have a special offer just for you. Would you like to hear more?
Patterns for speech synthesis in Brand Voice Self Service
We recommend using audio patterns if you want to achieve a more expressive and human-like intonation in synthesized speech.
For example, a speaker records this audio:
Hi, this is Jane. I work at Thunderclouds. Is it a good time to talk?You like how this sounds when pronounced by a speaker. However, you will not be able to use this audio as some words need to be replaced based on context. So you need to mark up the transcript with variables:
Hi, this is Jane. I work at {company_name=Thunderclouds}. Is it a good time to talk?Use the original audio with proper intonations and the original text as a pattern for synthesis to preserve the speaker's intonation while replacing the variable parts. For example:
Hi, this is Jane. I work at New Doors. Is it a good time to talk?
Try to make your audio patterns as close as possible to what you are going to use for synthesis. If that is not possible during the data preparation stage, you can provide them later or train your model without them altogether — you will still be able to use pattern-based synthesis. However, the sooner you provide the pattern recordings, the better your results will be.
Note
The original audio pattern for synthesis with the Brand Voice Self Service voice should be recorded by the same speaker used to create the voice.
Texts for model training
If you do not plan to use the created voice to narrate books, cite long lists, or synthesize texts rich in specialized terminology, the SpeechKit team can help you prepare the texts for model training. However, you will still need to add 500-1,000 phrases that are specific to your particular use case. Before recording, you can send us the texts you prepared to check that the training data is diverse enough from the linguistic standpoint.
You will need to prepare the source data for the patterns yourself, as only you know how and to what end the synthesized voice will be used.
At least 30% of the training data should contain questions so that the trained voice could reproduce the interrogative tone in texts.
Requirements for all texts
Tip
The result of Brand Voice Self Service voice model training directly depends on training data. Make sure to meet the specified text requirements and recommendations to get a high-quality Brand Voice Self Service voice.
-
Each audio recording must have an absolutely accurate text transcript.
-
The recommended phrase length is no more than 250 characters.
-
Audio recordings should not include incomplete phrases.
ing time! He won't be happy about that. If you hadn't had that argument, you could have asked for anything you wa.
-
Texts must be free of grammatical errors.
-
When recording Russian speech, make sure to use the letter ё when needed in the pattern text. You cannot use е instead of ё in any synthesized text.
-
In homographs where the stress may be ambiguous, explicitly indicate the stressed vowel with the
+sign.The +import of goods from foreign countries.: Stress falls on the first syllable.
Goods they im+port from China.: Stress falls on the second syllable. -
The lines of text for synthesis cannot include numbers or abbreviations, such as 15 Smith st., bl. 3 or USD 13.10. Make sure to spell out all numbers and abbreviations.
Fifteen Smith street, block three.
Thirteen dollars and ten cents. -
In questions, specify which word should be **logically stressed** to indicate the intonation of an interrogative sentence.
The sentence Did the cat go to the forest? can be read in three different ways:
- Did the **cat** go to the forest? Meaning Who went to the forest? Was it really the cat?
- Did the cat **go** to the forest? Meaning Did the cat walk or run? or Was the action performed? Is the cat gone or not?
- Did the cat go **to the forest**? Meaning Where did the cat go and why? To the forest, outside, to look for a sausage?
In all sentences, the logical stress emphasizes the main meaning of the sentence.
Pattern requirements
-
The phrase for synthesis must not be longer than 250 characters, including the variable part.
-
The variable part should not exceed 25% of the total phrase. The same restriction applies to the duration of the variable part relative to the duration of the final audio.
-
A pattern must contain one phrase and one or more variables for replacement.
-
Variables must be marked up.
Phrase for a pattern audio:
Your flight from London to Madrid is on September the eighth.
List of variables:variable_name = '{date}', variable_value = 'september the eighth'.
Marked-up pattern text:Your flight from London to Madrid is on {date}. -
The names of variables must be constant within the same template.
Record audio files
General recommendations for audio recording
Noise and echo during recording directly affect the quality of training and performance of your speech synthesis model. For this reason, when recording audio for training and fine-tuning your model or patterns for synthesis, try to reduce sound reflection in the room. A perfect place for recording is a room equipped with acoustic panels. If recording in a household environment, you can reduce the echo with soft surfaces and furniture, such as carpet, upholstered sofa, etc.
Use equipment that has the same settings and location for any audio recording.
Make sure the sound engineer, speaker, and voice coach are different people. A voice coach is a professional who makes sure the speaker strictly follows the text without changing the manner of narration.
When recording any audio intended for your speech synthesis model, use the one phrase per file rule.
No inaccuracies, micro repeats, reservations, and word substitutions are allowed. Any speech defects in the recordings made for synthesis models substantially degrade the quality of the synthesized speech.
Each recording of a pattern or phrase for model training must have an absolutely accurate text transcript. Patterns, training phrases, and their transcripts must not contain grammatical errors.
Requirements for audio recordings
| Requirement | Value |
|---|---|
| Sampling frequency | 48 kHz |
| Audio bit depth | 16 bit PCM |
| Number of channels | 1 (mono) |
| Format | WAV |
| Length | max. 15 seconds |
| Silence intervals at the beginning and end | 100–200 ms |
Save all the audio recordings as a ZIP archive for uploading.
Upload your data
Use the Yandex DataSphere interface to upload text data and audio files. For detailed guidelines on how to upload them, fill out this form, contact your manager or technical support.
Frequently asked questions
Can I upload audio data with other characteristics?
You cannot upload audio data that does not meet the requirements.
Where will the voice be available?
In Yandex Cloud, by voice_id provided in advance. Voices can be provided in SpeechKit Hybrid format.