Анализ данных с помощью Jupyter
Yandex Query поддерживает интеграцию с Jupyter и VSCode через магические команды Python cell (%%yq) и line (%yq). Интеграция позволяет упростить рабочие процессы сбора и анализа данных, делая их более эффективными и удобными.
Чтобы анализировать данные Query с помощью Jupyter:
- Установите и настройте пакет yandex_query_magic.
- Попробуйте шаблонизацию запросов.
- Обработайте результаты выполнения.
Перед началом работы
-
Зарегистрируйтесь в Yandex Cloud и создайте платежный аккаунт:
- Перейдите в консоль управления, затем войдите в Yandex Cloud или зарегистрируйтесь.
- На странице Yandex Cloud Billing убедитесь, что у вас подключен платежный аккаунт, и он находится в статусе
ACTIVEилиTRIAL_ACTIVE. Если платежного аккаунта нет, создайте его и привяжите к нему облако.
Если у вас есть активный платежный аккаунт, вы можете создать или выбрать каталог, в котором будет работать ваша инфраструктура, на странице облака.
-
Получите доступ к окружению JupyterLab или Jupyter Notebook.
Установка и настройка пакета yandex_query_magic
Установите пакет yandex_query_magic, выполнив в ячейке ноутбука команду:
%pip install yandex_query_magic --upgrade
-
Установите пакет yandex_query_magic c помощью pip:
pip install yandex_query_magic --upgrade -
Включите Jupyter-расширение для элементов управления интерфейса в Jupyter Notebook:
%jupyter contrib nbextension install --userЕсли вы столкнетесь с ошибкой
"No module named 'notebook.base'", попробуйте перейти на версию Jupyter Notebook 6.4.12:pip install --upgrade notebook==6.4.12
Настройка пакета
Настройки пакета yandex_query_magic можно задать с помощью line команды yq_settings, где указываются необходимые аргументы:
%yq_settings --folder-id <идентификатор_каталога> ...
Доступные параметры:
--folder-id <идентификатор_каталога>— идентификатор каталога для выполнения запросов Query. По умолчанию используется каталог, где запущена виртуальная машина с Jupyter.--vm-auth— устанавливает режим аутентификации ключом учетной записи виртуальной машины. Подробнее в инструкции Работа с Yandex Cloud изнутри виртуальной машины.--env-auth <переменная_окружения_environment_variable>— устанавливает режим аутентификации авторизованным ключом, содержимое которого находится в переменной окружения (Environment Variable). Этот режим предназначен для работы в условиях, когда нет доступа к файловой системе компьютера, где установлен Jupyter. Например, в Yandex DataSphere. В этом случае создайте секрет DataSphere, а имя созданного секрета укажите в параметре--env-auth.--sa-file-auth <авторизованный_ключ>— устанавливает режим аутентификации авторизованными ключами. Подробнее в инструкции Создать авторизованный ключ.
Проверка работы пакета
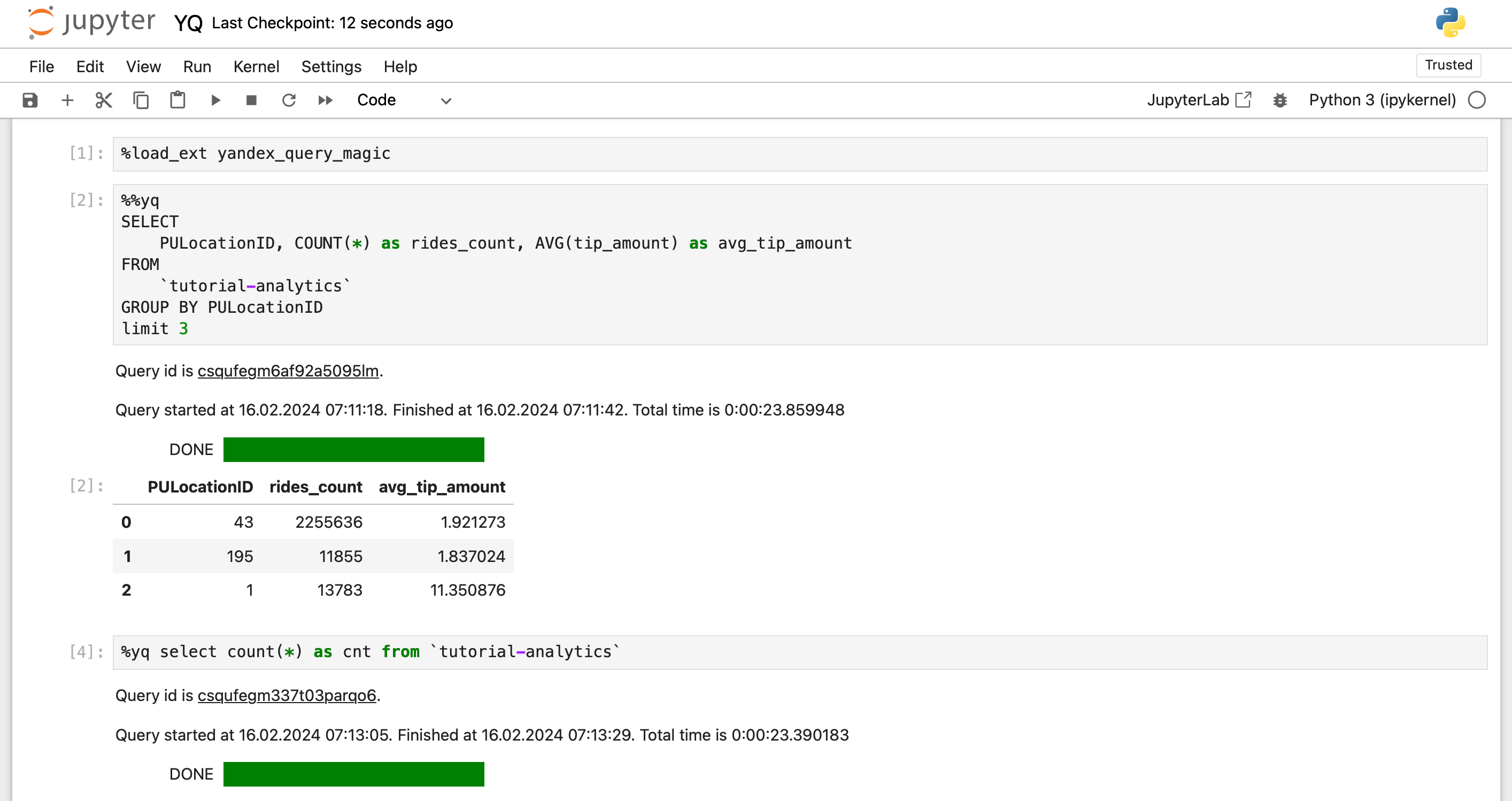
Команду %yq line magic можно использовать, когда весь SQL-запрос представлен одной строкой. В этом случае SQL-запрос выполняется с помощью ключевого слова %yq.
Если Jupyter запущен в виртуальной машине с привязанным к ней сервисным аккаунтом, загрузите расширение в Jupyter:
%load_ext yandex_query_magic
%yq SELECT "Hello, world!"
Где:
%yq— имя Jupyter magic.SELECT "Hello, world!"— текст запроса к Query.
Если к виртуальной машине не привязан сервисный аккаунт:
-
Создайте авторизованный ключ для сервисного аккаунта.
-
Выполните следующие команды, указав путь к файлу с авторизованным ключом:
%load_ext yandex_query_magic %yq_settings --sa-file-auth '<путь_к_файлу_с_ключом>' %yq SELECT "Hello, world!"Например:
%load_ext yandex_query_magic %yq_settings --sa-file-auth '/home/test/authorized_key.json' %yq SELECT "Hello, world!"Путь к файлу
authorized_key.jsonуказывается относительно директории, в которой сохранен файл с текущим Jupyter Notebook.
Чтобы выполнять многострочные SQL-запросы, необходимо использовать %%yq cell magic. Текст запроса должен начинаться с ключевого слова %%yq:
%%yq --folder-id <идентификатор_каталога> --name "Мой запрос" --description "Тестовый запрос" --raw-results
SELECT
col1,
COUNT(*)
FROM table
GROUP BY col1
Где:
--folder-id— идентификатор каталога для выполнения запроса Query. По умолчанию используется каталог, указанный ранее через%yq_settings. Если он не указан, то используется каталог, в котором запущена виртуальная машина.--name— имя запроса.--description— описание запроса.--raw-results— возвращает необработанные результаты выполнения запроса в Query. Спецификация формата доступна в разделе Соответствие YQL и Json-типов.
Шаблонизация запросов с помощью mustache-синтаксиса
Шаблоны вычислений между Jupyter и Query можно использовать для работы с запросами, а также для выполнения типовых операций без написания кода на языках программирования. Для этого в Query встроена поддержка написания запросов в mustache-синтаксисе, когда все ключевые слова и директивы шаблонов размещаются внутри ключевых символов {{}}. Mustache-синтаксис можно использовать с Jinja2 или во встроенном интерпретаторе Mustache-синтаксиса.
Встроенные mustache-шаблоны {{ yq-name }} позволяют передавать переменные из среды исполнения Jupyter прямо внутрь SQL-запросов. При этом передаваемые переменные автоматически будут конвертированы в нужные структуры данных Query. Например:
myQuery = "select * from Departments"
%yq {{myQuery}}
Mustache-строка {{myQuery}} будет интерпретирована как название переменной, откуда нужно взять текст. При этом в Query будет отправлен для исполнения текст select * from Departments.
Использование mustache-шаблонов упрощает интеграцию между Jupyter и Query. Например, у вас есть Python list lst=["Academy", "Physics"], содержащий названия департаментов, данные из которых вы хотите обработать. Без поддержки mustache-синтаксиса в Query вам предварительно нужно было бы превратить Python list в строку и передать ее в SQL запрос. Пример запроса:
var lstStr = ",".join(lst)
sqlQuery = f'select "Academy" in ListCreate({lstStr});
%yq {{sqlQuery}}
То есть для работы со сложными типами данных нужно знать детали синтаксиса SQL Query. При использовании mustache-синтаксиса запрос можно написать проще:
%yq select "Academy" in {{lst}}
При этом lst будет распознан как Python list и будет автоматически вставлена правильная SQL-конструкция для работы со списками. В данном случае в результате всех преобразований в Query будет отправлен следующий текст запроса:
%yq select "Academy" in ListCreate("Academy", "Physics") as lst
Jinja2
При типовой работе в Jupyter и Query рекомендуется использовать встроенный mustache-синтаксис. Если вам нужны расширенные возможности шаблонизации, используйте шаблоны Jinja2.
Чтобы установить Jinja2, выполните команду:
%pip install Jinja2
Пример использования Jinja-шаблона с циклом for:
{% for user in users %}
command = "select * from users where name='{{ user }}'"
{% endfor %}
Также c помощью Jinja-шаблонов можно выполнять различные операции обработки данных. В следующем примере, в зависимости от департамента, где обучается студент, выполняются различные операции над названием департамента:
{% if student.department == "Academy" %}
{{ student.department|upper }}
{% elif upper(student.department) != "MATHS DEPARTMENT" %}
{{ student.department|capitalize }}
{% endif %}
Чтобы указать Jinja, что конвертация должна выполняться по правилам Query, используйте специальный фильтр to_yq. Например, Python list lst=["Academy", "Physics"] из предыдущего примера в Jinja-шаблоне будет иметь вид:
%%yq --jinja2
select "Academy" in {{lst|to_yq}}
В случаях, когда нужно отключить шаблонизацию, используйте аргумент --no-var-expansion:
%%yq --no-var-expansion
...
Встроенные mustache-шаблоны
Встроенные mustache-шаблоны в Yandex Query включены по умолчанию и с их помощью удобно выполнять базовые операции работы с переменными Jupyter:
lst=["Academy", "Physics"]
%yq select "Academy" in {{lst}}
Использование переменных Pandas DataFrame
Пример использования пакета yandex_query_magic и mustache-синтаксиса с Pandas DataFrame:
-
Объявите переменную в Jupyter:
df = pandas.DataFrame({'_float': [1.0], '_int': [1], '_datetime': [pd.Timestamp('20180310')], '_string': ['foo']})
df может использоваться как переменная в запросах к Yandex Query. Во время выполнения запроса значение из переменной df используется для создания временной таблицы с тем же названием, df. Временная таблица может использоваться в пределах текущего исполняемого запроса в Yandex Query.
-
Получите данные:
%%yq SELECT * FROM mytable INNER JOIN {{df}} ON mytable.id=df._int
Таблица соответствия типов Pandas и типов Query:
| Тип Pandas | Тип YQL | Примечание |
|---|---|---|
| int64 | Int64 | При выходе значения за диапазон int64 возникнет ошибка выполнения SQL-запроса |
| float64 | Double | |
| datetime64[ns] | Timestamp | Точность до микросекунд. При задании наносекунд (поле nanosecond) возвращается исключение |
| str | String |
Использование переменных Python dict
Пример использования yandex_query_magic и mustache-синтаксиса с Python dict:
-
Объявите переменную в Jupyter:
dct = {"a": "1", "b": "2", "c": "test", "d": "4"}Теперь переменная
dctможет использоваться напрямую в запросах Query. Во время выполнения запросаdctбудет преобразован в соответствующий объект YQL Dict:Ключ Значение а "1" b "2" c "test" d "4" -
Получите данные:
%%yq SELECT "a" in {{dct}}
Таблица соответствия типов Python dict и типов Query:
| Тип Python | Тип YQL | Примечание |
|---|---|---|
| int | Int64 | При выходе значения за диапазон int64 возникнет ошибка выполнения SQL-запроса |
| float | Double | |
| datetime | Timestamp | |
| str | String |
Словарь также можно преобразовать в таблицу Pandas DataFrame с помощью конструктора:
df = pandas.DataFrame(dct)
Использование переменных Python list
Пример использования yandex_query_magic и mustache-синтаксиса с Python list:
-
Объявите переменную в Jupyter:
lst = [1,2,3]Тогда переменная
lstможет использоваться напрямую в запросах Query. Во время выполнения запросаlstбудет преобразован в соответствующий объект YQL List. -
Получите данные:
%%yq SELECT 1 IN {{lst}}
Таблица соответствия типов Python list и типов Query:
| Тип Python | Тип YQL | Примечание |
|---|---|---|
| int | Int64 | При выходе значения за диапазон int64 возникнет ошибка выполнения SQL-запроса |
| float | Double | |
| datetime | Timestamp | |
| str | String |
Список также можно преобразовать в таблицу Pandas DataFrame с помощью конструктора:
df = pandas.DataFrame(lst,
columns =['column1', 'column2', 'column3'])
Шаблоны Jinja
Шаблоны Jinja удобно использовать для создания SQL-запросов. Они позволяют автоматически вставлять в них разные данные, например, условия поиска, без необходимости писать каждый запрос вручную. Это упрощает работу, избавляет от ошибок и делает код более понятным.
Используя шаблоны Jinja, можно также автоматизировать создание запросов с повторяющимися элементами, добавляя, например, список значений для проверки в запросе, с помощью циклов в самом шаблоне. Это делает процесс ещё более гибким и экономит время на написание сложных запросов, когда нужно работать с множеством данных.
Ниже показано как отфильтровать данные в Yandex Query, используя переменную Python.
-
Объявите переменную в Jupyter:
name = "Ivan" -
Выполняя следующий код в ячейке Jupyter, обратите внимание, что для интерпретации SQL-запросов как Jinja2-шаблонов перед исполнением необходимо указать флаг
jinja2:%%yq <другие_параметры> --jinja2 SELECT "{{name}}"Параметры:
Фильтр to_yq
Шаблонизатор Jinja2 является системой шаблонизации общего назначения. При работе со значениями переменных Jinja2 использует стандартное строковое представление типов данных.
Например, задан Python list lst=["Academy", "Physics"], использовать его в Jinja-шаблоне можно так:
%%yq --jinja2
select "Academy" in {{lst}}
В результате исполнения мы получим ошибку Unexpected token '['. Ошибка возникает из-за того, что шаблонизатор Jinja конвертирует переменную lst в строку ["Academy", "Physics"] по правилам Python, без учета специфики SQL-запросов в Yandex Query.
Для указания, что конвертация должна выполняться по правилам Yandex Query, необходимо использовать фильтр to_yq. Тогда тот же запрос в Jinja-синтаксисе будет выглядеть так:
%%yq --jinja2
select "Academy" in {{lst|to_yq}}
Jinja-фильтр to_yq выполняет преобразование данных в синтаксис Yandex Query полностью аналогично встроенным mustache-шаблонам.
Захват результатов выполнения команд
Результат исполнения line magic command может быть захвачен с помощью команды присваивания:
varname = %yq <запрос>
Результат выполнения cell magic command можно захватить, указав имя переменной в начале текста запроса и оператор <<:
%%yq
varname << <запрос>
После этого результат выполнения можно использовать, как обычную переменную Jupyter.
Например, захватим результат выполнения команды в переменные output с помощью cell magic:
output = %yq SELECT 1 as column1
А в данном примере захватим результат выполнения в переменную output2 с помощью line magic:
%%yq
output2 << SELECT 'Two' as column2, 3 as column3
Далее эти переменные можно использовать, как обычные переменные IPython. Например, можно вывести их на печать:
output
По умолчанию результатом выполнения команд %yq и %%yq является Pandas DataFrame с колонками, совпадающими с названиями колонок из SQL-запроса и со строками, содержащими результаты запроса. Конвертацию в Pandas DataFrame можно отключить с помощью аргумента --raw-results.
В примере выше переменная output будет обладать следующей структурой:
| column1 | |
|---|---|
| 0 | 1 |
Переменная output2 будет выглядить следующим образом:
| column2 | column3 | |
|---|---|---|
| 0 | Two | 3 |
Если запрос не предполагает возврат результатов (например, insert into table select * from another_table), то возвращаемым значением будет None. Если в результате выполнения запроса было возвращено несколько наборов результатов, то они будут представлены в виде списка (list) из отдельных результатов.
Во время выполнения запроса пакет yandex_query_magic выводит дополнительную информацию. Например: идентификатор запроса, время начала и продолжительность выполнения запроса:

Чтобы скрыть отображение прогресса выполнения для ячейки, можно использовать дополнительную команду %%capture.
%%capture
%%yq
<запрос>
В этом случае информация о ходе прогресса исполнения не будет выводиться в консоль.