MATCH_RECOGNIZE

Выражение MATCH_RECOGNIZE выполняет распознавание паттерна в последовательности строк и возвращает найденные результаты. Данная функциональность важна для различных сфер деятельности, таких как выявление мошенничества, анализ ценообразования в сфере финансов и обработка данных датчиков. Эта область известна как Complex Event Processing (CEP), и распознавание паттерна является важным инструментом для этого. Пример работы MATCH_RECOGNIZE приведен по ссылке.
Алгоритм обработки данных
Выражение MATCH_RECOGNIZE выполняет следующие действия:
- Входная таблица или поток данных разбивается на непересекающиеся группы. Каждая группа состоит из строк входного набора данных с одинаковыми значениями в колонках, перечисленных после
PARTITION BY. - Каждая группа упорядочивается в соответствии с блоком
ORDER BY. Для потока данных используется сортировка на окне. - В каждой упорядоченной группе независимо выполняется распознавание паттерна из
PATTERN. - Поиск паттерна в последовательности строк проходит пошагово: строки одна за другой проверяются на соответствие паттерну. Среди всех совпадений, начинающихся в первой строке, выбирается то, которое состоит из наибольшего количества строк. Если не было найдено совпадений с началом в первой строке, то поиск продолжается, начиная со следующей строки.
- После нахождения совпадения вычисляются колонки, задающиеся выражениями в блоке
MEASURES. - В зависимости от режима
ROWS PER MATCHвыводится одна или все строки для найденного совпадения. - Режим
AFTER MATCH SKIPопределяет, с какой строки возобновится распознавание паттерна.
Синтаксис
MATCH_RECOGNIZE (
[ PARTITION BY <партиция_1> [ ... , <партиция_N> ] ]
[ ORDER BY <ключ_сортировки_1> [ ... , <ключ_сортировки_N> ] ]
[ MEASURES <выражение_1> AS <имя_колонки_1> [ ... , <выражение_N> AS <имя_колонки_N> ] ]
[ ROWS PER MATCH ]
[ AFTER MATCH SKIP ]
PATTERN (<паттерн_для_поиска>)
DEFINE <переменная_1> AS <предикат_1> [ ... , <переменная_N> AS <предикат_N> ]
)
Описание элементов SQL-синтаксиса выражения MATCH_RECOGNIZE:
DEFINE– блок объявления переменных, с помощью которых описывается паттерн для поиска, и условий, которым должны соответствовать строки для каждой из переменных.PATTERN– регулярное выражение, описывающее искомый паттерн для поиска.MEASURESопределяет набор колонок для возвращаемых данных. Каждая колонка задаётся SQL-выражением для ее вычисления.ROWS PER MATCHопределяет структуру возвращаемых данных и количество строк по каждому найденному совпадению.AFTER MATCH SKIPопределяет способ перехода к месту поиска следующего совпадения.ORDER BYопределяет сортировку входных данных. Поиск паттернов выполняется внутри данных, упорядоченных в соответствии со списком колонок или выражениями, перечисленными в<ключ_сортировки_1> [ ... , <ключ_сортировки_N> ].PARTITION BYразделяет входной набор данных по заданным правилам в соответствии с<партиция_1> [ ... , <партиция_N> ]. В каждой из частей поиск паттернов производится независимо.
DEFINE
DEFINE <переменная_1> AS <предикат_1> [ ... , <переменная_N> AS <предикат_N> ]
С помощью DEFINE объявляются переменные, на основе которых описывается искомый паттерн, задаваемый в PATTERN. Переменные – это именованные SQL-выражения, вычисляемые над входными данными. Синтаксис SQL-выражений в DEFINE совпадает с SQL-выражениями предиката WHERE. Например, выражение button = 1 выполняет поиск строк со значением 1 в колонке button. В качестве условий могут выступать любые SQL-выражения, с помощью которых можно выполнять поиск, включая функции агрегации (LAST, FIRST). Например, button > 2 AND zone_id < 12 или LAST(button) > 10.
В примере ниже SQL-выражение A.button = 1 объявлено как переменная A.
DEFINE
A AS A.button = 1
Примечание
В настоящий момент в DEFINE не поддерживаются функции агрегации, такие как AVG, MIN, MAX, и функции PREV и NEXT.
При обработке очередной строки данных производится вычисление всех SQL-выражений, описывающих переменные в DEFINE. Когда SQL-выражение, описывающее соответствующую переменную из DEFINE, принимает значение ИСТИНА (TRUE), то такая строка получает метку с названием переменной DEFINE и добавляется к списку рассматриваемых на совпадение с паттернами.
Пример
При описании переменных в SQL-выражениях можно использовать ссылки на другие переменные:
DEFINE
A AS A.button = 1 AND LAST(A.zone_id) = 12,
B AS B.button = 2 AND FIRST(A.zone_id) = 12
Строка входных данных будет вычислена как переменная A, если в ней присутствует колонка button со значением 1, а в последней строке из множества ранее совпавших с переменной A есть колонка zone_id со значением 12. Строка будет вычислена как переменная B, если в строке данных присутствует колонка button со значением 2, а в первой строке из множества ранее совпавших с переменной A есть колонка zone_id со значением 12.
PATTERN
PATTERN (<паттерн_для_поиска>)
Ключевое слово PATTERN описывает искомый паттерн для поиска в виде, вычисляющийся на основе переменных из блока DEFINE. Синтаксис PATTERN схож с синтаксисом регулярных выражений.
Важно
Если переменная, использованная в блоке PATTERN, не была предварительно описана в блоке DEFINE, то считается, что она всегда принимает значение TRUE.
В PATTERN можно использовать квантификаторы. Они в регулярных выражениях определяют число повторений элемента или подпоследовательности в паттерне для нахождения совпадения. Приведем перечень поддерживаемых квантификаторов:
| Квантификатор | Описание |
|---|---|
A+ |
Одно или несколько повторений переменной A |
A* |
Ноль или несколько повторений переменной A |
A? |
Ноль или одно повторение переменной A |
B{n} |
Ровно n повторений переменной B |
C{n, m} |
От n до m повторений переменной C |
D{n,} |
Не менее n повторений переменной D |
(A|B) |
Появление переменной A или B в данных |
(A|B){,m} |
От нуля до m повторений переменной A или B |
Поддерживаемые последовательности поиска паттернов:
| Поддерживаемые последовательности | Синтаксис | Описание |
|---|---|---|
| Последовательность | A B+ C+ D+ |
Производится поиск точной указанной последовательности, не допускается появление других переменных внутри последовательности. Поиск паттерна производится в порядке указания переменных паттерна. |
| Один из | A | B | C |
Переменные перечисляются в любом порядке с указанием символа | между ними. Производится поиск любой переменной из указанного списка. |
| Группировка | (A | B)+ | C |
Переменные внутри круглых скобок считаются единой группой. В этом случае квантификаторы применяются ко всей группе сразу. |
| Исключение из результата | {- A B+ C -} |
При выборе режима ALL ROWS PER MATCH строки, найденные по паттерну в скобках, будут исключены из результата |
Пример
PATTERN (B1 E* B2+ B3)
DEFINE
B1 as B1.button = 1,
B2 as B2.button = 2,
B3 as B3.button = 3
В блоке DEFINE описаны переменные B1, B2, B3. Переменная E в блоке DEFINE не описана. Такая запись позволяет интерпретировать E как любое событие, поэтому будет искаться следующий паттерн: одно нажатие кнопки 1, одно или более нажатий кнопки 2 и одно нажатие кнопки 3. При этом между нажатием кнопки 1 и кнопки 2 может быть произвольное число любых других событий.
MEASURES
MEASURES <выражение_1> AS <имя_колонки_1> [ ... , <выражение_N> AS <имя_колонки_N> ]
MEASURES описывает набор возвращаемых колонок при нахождении паттерна. Набор возвращаемых колонок должен быть представлен SQL-выражением c агрегирующими функциями над переменными, объявленными в конструкции DEFINE.
Пример
Входными данными для примера являются:
| ts | button | device_id | zone_id |
|---|---|---|---|
| 100 | 1 | 3 | 0 |
| 200 | 1 | 3 | 1 |
| 300 | 2 | 2 | 0 |
| 400 | 3 | 1 | 1 |
MEASURES
AGGREGATE_LIST(B1.zone_id * 10 + B1.device_id) AS ids,
COUNT(DISTINCT B1.zone_id) AS count_zones,
LAST(B3.ts) - FIRST(B1.ts) AS time_diff,
42 AS meaning_of_life
PATTERN (B1+ B2 B3)
DEFINE
B1 AS B1.button = 1,
B2 AS B2.button = 2,
B3 AS B3.button = 3
Результат:
| ids | count_zones | time_diff | meaning_of_life |
|---|---|---|---|
| [3,13] | 2 | 300 | 42 |
Колонка ids содержит список значений zone_id * 10 + device_id, посчитанных среди совпавших с переменной B1 строк. Колонка count_zones содержит количество уникальных значений колонки zone_id среди совпавших с переменной B1 строк. Колонка time_diff содержит разницу между значением колонки ts в последней строке из множества совпавших с переменной B3 и значением колонки ts в первой строке из множества совпавших с переменной B1. Колонка meaning_of_life содержит константу 42. Таким образом, выражение в MEASURES может содержать агрегирующие функции над несколькими переменными, но внутри одной агрегирующей функции должна быть только одна переменная.
ROWS PER MATCH
ROWS PER MATCH определяет количество строк результата для каждого найденного совпадения, а также множество возвращаемых колонок. Режим по умолчанию - ONE ROW PER MATCH.
ONE ROW PER MATCH устанавливает режим работы ROWS PER MATCH на вывод одной строки для найденного совпадения. Структура возвращаемых данных соответствует колонкам, перечисленным в PARTITION BY и MEASURES.
ALL ROWS PER MATCH устанавливает режим работы ROWS PER MATCH на вывод всех строк для найденного совпадения, кроме явно исключенных скобками. Помимо колонок исходного набора данных структура возвращаемых данных включает в себя колонки, перечисленные в MEASURES.
Примеры
Входными данными для всех примеров являются:
| ts | button |
|---|---|
| 100 | 1 |
| 200 | 2 |
| 300 | 3 |
Пример 1
MEASURES
FIRST(B1.ts) AS first_ts,
FIRST(B2.ts) AS mid_ts,
LAST(B3.ts) AS last_ts
ONE ROW PER MATCH
PATTERN (B1 {- B2 -} B3)
DEFINE
B1 AS B1.button = 1,
B2 AS B2.button = 2,
B3 AS B3.button = 3
Результат:
| first_ts | mid_ts | last_ts |
|---|---|---|
| 100 | 200 | 300 |
Пример 2
MEASURES
FIRST(B1.ts) AS first_ts,
FIRST(B2.ts) AS mid_ts,
LAST(B3.ts) AS last_ts
ALL ROWS PER MATCH
PATTERN (B1 {- B2 -} B3)
DEFINE
B1 AS B1.button = 1,
B2 AS B2.button = 2,
B3 AS B3.button = 3
Результат:
| first_ts | mid_ts | last_ts | button | ts |
|---|---|---|---|---|
| 100 | 200 | 300 | 1 | 100 |
| 100 | 200 | 300 | 3 | 300 |
AFTER MATCH SKIP
AFTER MATCH SKIP определяет способ перехода от найденного совпадения к поиску следующего. В режиме AFTER MATCH SKIP TO NEXT ROW поиск следующего совпадения начинается после первой строки предыдущего, в режиме AFTER MATCH SKIP PAST LAST ROW - после последней строки предыдущего совпадения. Режим по умолчанию - PAST LAST ROW.
Примеры
Входными данными для всех примеров являются:
| ts | button |
|---|---|
| 100 | 1 |
| 200 | 1 |
| 300 | 2 |
| 400 | 3 |
Пример 1
MEASURES
FIRST(B1.ts) AS first_ts,
LAST(B3.ts) AS last_ts
AFTER MATCH SKIP TO NEXT ROW
PATTERN (B1+ B2 B3)
DEFINE
B1 AS B1.button = 1,
B2 AS B2.button = 2,
B3 AS B3.button = 3
Результат:
| first_ts | last_ts |
|---|---|
| 100 | 400 |
| 200 | 400 |
Пример 2
MEASURES
FIRST(B1.ts) AS first_ts,
LAST(B3.ts) AS last_ts
AFTER MATCH SKIP PAST LAST ROW
PATTERN (B1+ B2 B3)
DEFINE
B1 AS B1.button = 1,
B2 AS B2.button = 2,
B3 AS B3.button = 3
Результат:
| first_ts | last_ts |
|---|---|
| 100 | 400 |
ORDER BY
ORDER BY <ключ_сортировки_1> [ ... , <ключ_сортировки_N> ]
<ключ_сортировки> ::= { <имена_колонок> | <выражение> }
ORDER BY определяет сортировку входных данных. То есть перед выполнением всех операций поиска паттернов, данные будут предварительно отсортированы по указанным ключам или выражениям. Синтаксис аналогичен SQL-выражению ORDER BY.
Пример
ORDER BY CAST(ts AS Timestamp)
Особенности сортировки в потоковых запросах
Потоковые данные потенциально бесконечны, поэтому для их сортировки используется упорядочивание на окне (TimeOrderRecover). Для этого алгоритма в качестве столбцов сортировки можно задавать ровно одно выражение с типом Timestamp, причем сортировка допустима только в направлении возрастания значений, ASC. Управлять размерами окна можно с помощью следующих параметров:
- TimeOrderRecoverAhead, размерность микросекунды, default = -10'000'000 (-10s), должно быть < 0;
- TimeOrderRecoverDelay, размерность микросекунды, default = 10'000'000 (10s), должно быть > 0;
- TimeOrderRecoverRowLimit, размерность число строк, default = 1'000'000, должно быть > 0.
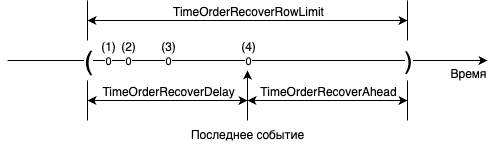
Сортировка на окне работает по следующему алгоритму:
- Если событие не попало в окно, то оно проходит дальше без сортировки.
- Если событие попало в левую половину окна, то оно попадает в сортировку.
- Если число событий в окне превышает
TimeOrderRecoverRowLimit, то самое старое событие окна покидаетTimeOrderRecoverи попадает вMATCH_RECOGNIZE. - Если событие попало в правую половину окна, то окно сдвигается вправо, и новоприбывшее событие становится
Latest row. Все события, выпавшие из окна, покидаютTimeOrderRecoverи попадают вMATCH_RECOGNIZE.
Примеры
Пример 1
Не важно, что события могут сильно убегать вперед, но при этом важно, что могут быть отставания в час:
PRAGMA config.flags("TimeOrderRecoverDelay", "-3600000000"); -- -1 час
PRAGMA config.flags("TimeOrderRecoverAhead", "3155760000000000"); -- 100 лет
Пример 2
Не хочется, чтобы события из далекого будущего ломали окно сортировки, при этом известно, что события гарантированно приходят хотя бы раз в час:
PRAGMA config.flags("TimeOrderRecoverDelay", "-3600000000"); -- -1 час
PRAGMA config.flags("TimeOrderRecoverAhead", "3600000000"); -- 1 час
PARTITION BY
PARTITION BY <партиция_1> [ ... , <партиция_N> ]
<партиция> ::= { <имена_колонок> | <выражение> }
PARTITION BY - выражение разбивает исходные данные на несколько непересекающихся групп, в каждой из которых независимо производится поиск паттернов. Если выражение не указывается, то все данные обрабатываются в виде единой группы. В группу попадают записи с одинаковыми значениями колонок, перечисленных после PARTITION BY.
Пример
PARTITION BY device_id, zone_id
Ограничения
Степень поддержки выражения MATCH_RECOGNIZE со временем будет соответствовать стандарту SQL-2016, однако сейчас действует следующий набор ограничений:
ORDER_BY. В потоковых запросах в качестве столбцов сортировки можно задавать ровно одно выражение с типомTimestamp, причем сортировка допустима только в направлении возрастания значений,ASC.MEASURES. Не поддерживаются функцииPREV/NEXT.AFTER MATCH SKIP. Поддерживаются только режимыAFTER MATCH SKIP TO NEXT ROWиAFTER MATCH SKIP PAST LAST ROW.PATTERN. Не реализованы Union pattern variables.DEFINE. Не поддерживаются агрегатные функции.
Пример использования
Разберем практический пример распознавания паттернов в потоке данных, созданном IoT-устройством с кнопками и событиями, вызываемыми при их активации. Нам нужно найти и обработать следующую последовательность нажатия кнопок: кнопка 1, кнопка 2, кнопка 3.
Структура передаваемых данных:
| ts | button | device_id | zone_id |
|---|---|---|---|
| 600 | 3 | 17 | 3 |
| 500 | 3 | 4 | 2 |
| 400 | 2 | 17 | 3 |
| 300 | 2 | 4 | 2 |
| 200 | 1 | 17 | 3 |
| 100 | 1 | 4 | 2 |
Тело SQL-запроса:
PRAGMA FeatureR010="prototype"; -- прагма для включения MATCH_RECOGNIZE
SELECT * FROM input MATCH_RECOGNIZE ( -- выполняем поиск паттернов из потока input
PARTITION BY device_id, zone_id -- разбиваем данные на группы по колонкам device_id и zone_id
ORDER BY ts -- просматриваем события в порядке возрастания значения колонки ts
MEASURES
LAST(B1.ts) AS b1, -- в результатах запроса будем получать последний момент нажатия на кнопку 1
LAST(B3.ts) AS b3 -- в результатах запроса будем получать последний момент нажатия на кнопку 3
ONE ROW PER MATCH -- будем получать одну строку результатов на найденное совпадение
AFTER MATCH SKIP TO NEXT ROW -- после нахождения совпадения перейдем на следующую строку
PATTERN (B1 B2+ B3) -- ищем паттерн, состоящий из одного нажатия на кнопку 1, одного или нескольких нажатий на кнопку 2 и одного нажатия на кнопку 3
DEFINE
B1 AS B1.button = 1, -- определяем переменную B1 как событие нажатия кнопки 1 (значение поля button равно 1)
B2 AS B2.button = 2, -- определяем переменную B2 как событие нажатия кнопки 2 (значение поля button равно 2)
B3 AS B3.button = 3 -- определяем переменную B3 как событие нажатия кнопки 3 (значение поля button равно 3)
);
Результат:
| b1 | b3 | device_id | zone_id |
|---|---|---|---|
| 100 | 500 | 4 | 2 |
| 200 | 600 | 17 | 3 |