Создание сервера MLFlow для логирования экспериментов и артефактов

В практическом руководстве показано, как развернуть MLFlow Tracking Server для логирования экспериментов и артефактов на отдельной виртуальной машине Yandex Compute Cloud. Эксперименты будут проводиться в JupyterLab Notebook. Для хранения внутренних объектов будет использоваться база данных Yandex Managed Service for PostgreSQL, а для хранения артефактов — бакет Yandex Object Storage.
Чтобы создать сервер MLFlow для логирования экспериментов и артефактов JupyterLab Notebook:
- Подготовьте инфраструктуру.
- Создайте статический ключ доступа.
- Создайте пару ключей SSH.
- Создайте виртуальную машину.
- Создайте управляемую БД.
- Создайте бакет.
- Установите MLFlow Tracking Server и добавьте его в автозагрузку ВМ.
- Создайте секреты.
- Обучите модель.
Если созданные ресурсы вам больше не нужны, удалите их.
Перед началом работы
Перед началом работы нужно зарегистрироваться в Yandex Cloud, настроить сообщество и привязать к нему платежный аккаунт:
- На главной странице DataSphere нажмите Попробовать бесплатно и выберите аккаунт для входа — Яндекс ID или рабочий аккаунт в федерации (SSO).
- Выберите организацию Yandex Identity Hub, в которой вы будете работать в Yandex Cloud.
- Создайте сообщество.
- Привяжите платежный аккаунт к сообществу DataSphere, в котором вы будете работать. Убедитесь, что у вас подключен платежный аккаунт, и он находится в статусе
ACTIVEилиTRIAL_ACTIVE. Если платежного аккаунта нет, создайте его в интерфейсе DataSphere.
Необходимые платные ресурсы
- Кластер Managed Service for PostgreSQL: выделенные хостам вычислительные ресурсы, объем хранилища и резервных копий (тарифы Managed Service for PostgreSQL).
- Виртуальная машина: использование вычислительных ресурсов, хранилища, публичного IP-адреса и операционной системы (тарифы Compute Cloud).
- Бакет Object Storage: использование хранилища и выполнение операций с данными (тарифы Object Storage).
- Проект DataSphere: использование вычислительных ресурсов и хранилища (тарифы DataSphere).
Подготовьте инфраструктуру
Войдите в консоль управления Yandex Cloud и выберите организацию, в которой вы работаете с DataSphere. На странице Yandex Cloud Billing убедитесь, что у вас подключен платежный аккаунт.
Если у вас есть активный платежный аккаунт, на странице облака вы можете создать или выбрать каталог, в котором будет работать ваша инфраструктура.
Примечание
Если вы работаете с Yandex Cloud через федерацию удостоверений, вам может быть недоступна платежная информация. В этом случае обратитесь к администратору вашей организации в Yandex Cloud.
Создайте каталог
- В консоли управления выберите облако и нажмите кнопку Создать каталог.
- Введите имя каталога, например,
data-folder. - Нажмите кнопку Создать.
Создайте сервисный аккаунт для Object Storage
Для доступа к бакету в Object Storage вам понадобится сервисный аккаунт с ролями storage.viewer и storage.uploader.
- В консоли управления перейдите в каталог
data-folder. - Перейдите в сервис Identity and Access Management.
- Нажмите кнопку Создать сервисный аккаунт.
- Введите имя сервисного аккаунта, например,
datasphere-sa. - Нажмите Добавить роль и назначьте сервисному аккаунту роли
storage.viewerиstorage.uploader. - Нажмите кнопку Создать.
Создайте статический ключ доступа
Чтобы получить доступ к Object Storage из DataSphere, вам понадобится статический ключ.
- В консоли управления перейдите в каталог, которому принадлежит сервисный аккаунт.
- Перейдите в сервис Identity and Access Management.
- На панели слева выберите Сервисные аккаунты.
- В открывшемся списке выберите сервисный аккаунт
datasphere-sa. - На верхней панели нажмите кнопку Создать новый ключ.
- Выберите Создать статический ключ доступа.
- Задайте описание ключа и нажмите кнопку Создать.
- Сохраните идентификатор и секретный ключ. После закрытия диалога значение ключа будет недоступно.
-
Создайте ключ доступа для сервисного аккаунта
datasphere-sa:yc iam access-key create --service-account-name datasphere-saРезультат:
access_key: id: aje6t3vsbj8l******** service_account_id: ajepg0mjt06s******** created_at: "2022-07-18T14:37:51Z" key_id: 0n8X6WY6S24N7Oj***** secret: JyTRFdqw8t1kh2-OJNz4JX5ZTz9Dj1rI9hx***** -
Сохраните идентификатор
key_idи секретный ключsecret. Получить значение ключа снова будет невозможно.
Создайте пару ключей SSH
Чтобы подключаться к виртуальной машине по SSH, нужна пара ключей: открытый ключ размещается на ВМ, а закрытый ключ хранится у пользователя. Такой способ более безопасен, чем подключение по логину и паролю.
Примечание
В публичных образах Linux, предоставляемых Yandex Cloud, возможность подключения по протоколу SSH с использованием логина и пароля по умолчанию отключена.
Чтобы создать пару ключей:
-
Откройте терминал.
-
Создайте новый ключ с помощью команды
ssh-keygen:ssh-keygen -t ed25519 -C "<опциональный_комментарий>"Вы можете передать в параметре
-Cпустую строку, чтобы не добавлять комментарий, или не указывать параметр-Cвообще — в таком случае будет добавлен комментарий по умолчанию.После выполнения команды вам будет предложено указать имя и путь к файлам с ключами, а также ввести пароль для закрытого ключа. Если задать только имя, пара ключей будет создана в текущей директории. Открытый ключ будет сохранен в файле с расширением
.pub, закрытый ключ — в файле без расширения.По умолчанию команда предлагает сохранить ключ под именем
id_ed25519в директории/home/<имя_пользователя>/.ssh. Если в этой директории уже есть SSH-ключ с именемid_ed25519, вы можете случайно перезаписать его и потерять доступ к ресурсам, в которых он используется. Поэтому рекомендуется использовать уникальные имена для всех SSH-ключей.
Если у вас еще не установлен OpenSSH, установите его по инструкции.
-
Запустите
cmd.exeилиpowershell.exe(предварительно обновите PowerShell). -
Создайте новый ключ с помощью команды
ssh-keygen:ssh-keygen -t ed25519 -C "<опциональный_комментарий>"Вы можете передать в параметре
-Cпустую строку, чтобы не добавлять комментарий, или не указывать параметр-Cвообще — в таком случае будет добавлен комментарий по умолчанию.После выполнения команды вам будет предложено указать имя и путь к файлам с ключами, а также ввести пароль для закрытого ключа. Если задать только имя, пара ключей будет создана в текущей директории. Открытый ключ будет сохранен в файле с расширением
.pub, закрытый ключ — в файле без расширения.По умолчанию команда предлагает сохранить ключ под именем
id_ed25519в папкуC:\Users\<имя_пользователя>/.ssh. Если в этой директории уже есть SSH-ключ с именемid_ed25519, вы можете случайно перезаписать его и потерять доступ к ресурсам, в которых он используется. Поэтому рекомендуется использовать уникальные имена для всех SSH-ключей.
Создайте ключи с помощью приложения PuTTY:
-
Скачайте и установите PuTTY.
-
Добавьте папку с PuTTY в переменную
PATH:- Нажмите кнопку Пуск и в строке поиска Windows введите Изменение системных переменных среды.
- Справа снизу нажмите кнопку Переменные среды....
- В открывшемся окне найдите параметр
PATHи нажмите Изменить. - Добавьте путь к папке в список.
- Нажмите кнопку ОК.
-
Запустите приложение PuTTYgen.
-
В качестве типа генерируемой пары выберите EdDSA. Нажмите Generate и поводите курсором в поле выше до тех пор, пока не закончится создание ключа.
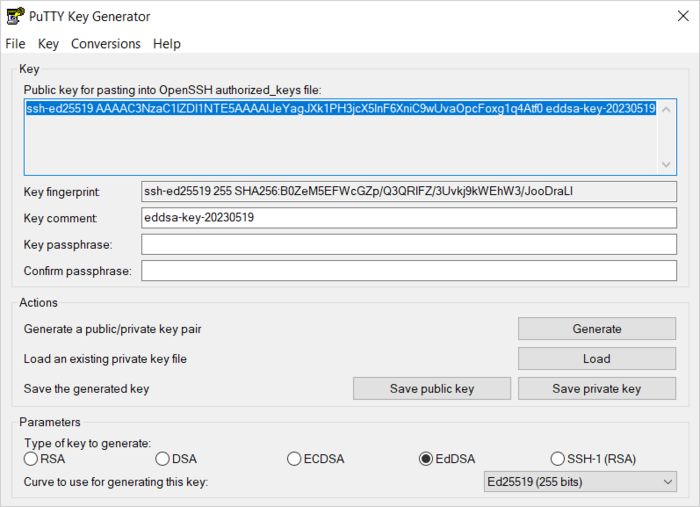
-
В поле Key passphrase введите надежный пароль. Повторно введите его в поле ниже.
-
Нажмите кнопку Save private key и сохраните закрытый ключ. Никому не сообщайте ключевую фразу от него.
-
Нажмите кнопку Save public key и сохраните открытый ключ в файле
<имя_ключа>.pub.
Создайте виртуальную машину
-
На странице каталога в консоли управления нажмите кнопку Создать ресурс и выберите
Виртуальная машина. -
В блоке Образ загрузочного диска в поле Поиск продукта введите
Ubuntu 22.04и выберите публичный образ Ubuntu 22.04. -
В блоке Расположение выберите зону доступности
ru-central1-a. -
В блоке Диски и файловые хранилища выберите тип диска
SSDи задайте размер20 ГБ. -
В блоке Вычислительные ресурсы перейдите на вкладку
Своя конфигурацияи укажите необходимую платформу, количество vCPU и объем RAM:- Платформа —
Intel Ice Lake. - vCPU —
2. - Гарантированная доля vCPU —
100%. - RAM —
4 ГБ.
- Платформа —
-
В блоке Сетевые настройки:
- В поле Подсеть выберите подсеть, которая указана в настройках проекта DataSphere. У подсети должен быть настроен NAT-шлюз.
- В поле Публичный IP-адрес оставьте значение
Автоматически, чтобы назначить ВМ случайный внешний IP-адрес из пула Yandex Cloud, или выберите статический адрес из списка, если вы зарезервировали его заранее.
-
В блоке Доступ выберите вариант SSH-ключ и укажите данные для доступа на ВМ:
- В поле Логин введите имя пользователя. Не используйте имя
rootили другие имена, зарезервированные ОС. Для выполнения операций, требующих прав суперпользователя, используйте командуsudo. -
В поле SSH-ключ выберите SSH-ключ, сохраненный в вашем профиле пользователя организации.
Если в вашем профиле нет сохраненных SSH-ключей или вы хотите добавить новый ключ:
-
Нажмите кнопку Добавить ключ.
-
Задайте имя SSH-ключа.
-
Выберите вариант:
-
Ввести вручную— вставьте содержимое открытого SSH-ключа. Пару SSH-ключей необходимо создать самостоятельно. -
Загрузить из файла— загрузите открытую часть SSH-ключа. Пару SSH-ключей необходимо создать самостоятельно. -
Сгенерировать ключ— автоматическое создание пары SSH-ключей.При добавлении сгенерированного SSH-ключа будет создан и загружен архив с парой ключей. В ОС на базе Linux или macOS распакуйте архив в папку
/home/<имя_пользователя>/.ssh. В ОС Windows распакуйте архив в папкуC:\Users\<имя_пользователя>/.ssh. Дополнительно вводить открытый ключ в консоли управления не требуется.
-
-
Нажмите кнопку Добавить.
SSH-ключ будет добавлен в ваш профиль пользователя организации. Если в организации отключена возможность добавления пользователями SSH-ключей в свои профили, добавленный открытый SSH-ключ будет сохранен только в профиле пользователя внутри создаваемого ресурса.
-
- В поле Логин введите имя пользователя. Не используйте имя
-
В блоке Общая информация задайте имя ВМ:
mlflow-vm. -
В блоке Дополнительно выберите сервисный аккаунт
datasphere-sa. -
Нажмите кнопку Создать ВМ.
Создайте управляемую БД
- В консоли управления выберите каталог, в котором нужно создать кластер БД.
- Перейдите в сервис Managed Service for PostgreSQL.
- Нажмите кнопку Создать кластер.
- Введите имя кластера, например
mlflow-bd. - В блоке Класс хоста выберите конфигурацию
s3-c2-m8. - В блоке Размер хранилища выберите
250 ГБ. - В блоке База данных введите имя пользователя и пароль. Они понадобятся для подключения.
- В блоке Хосты выберите зону доступности
ru-central1-a. - Нажмите кнопку Создать кластер.
- Зайдите в созданную БД и нажмите Подключиться.
- Сохраните ссылку на хост из поля
host— она понадобится для подключения.
Создайте бакет
- В консоли управления выберите каталог, в котором хотите создать бакет.
- Перейдите в сервис Object Storage.
- Справа сверху нажмите кнопку Создать бакет.
- В поле Имя укажите имя бакета, например
mlflow-bucket. - В полях Чтение объектов, Чтение списка объектов и Чтение настроек выберите С авторизацией.
- Нажмите кнопку Создать бакет.
- Чтобы создать папку для артефактов MLflow, зайдите в созданный бакет и нажмите Создать папку.
- Введите имя папки, например
artifacts.
Установите MLFlow Tracking Server и добавьте его в автозагрузку ВМ
-
Подключитесь к виртуальной машине через SSH.
-
Скачайте дистрибутив
Anaconda:curl --remote-name https://repo.anaconda.com/archive/Anaconda3-2023.07-1-Linux-x86_64.sh -
Запустите установку:
bash Anaconda3-2023.07-1-Linux-x86_64.shДождитесь окончания установки и перезапустите оболочку.
-
Создайте окружение:
conda create -n mlflow -
Активируйте окружение:
conda activate mlflow -
Установите необходимые пакеты, последовательно выполнив команды:
conda install -c conda-forge mlflow conda install -c anaconda boto3 pip install psycopg2-binary pip install pandas -
Создайте переменные окружения для доступа к S3:
-
Откройте файл с переменными:
sudo nano /etc/environment -
Добавьте в него следующие строки, подставив значение внутреннего IP вашей виртуальной машины:
MLFLOW_S3_ENDPOINT_URL=https://storage.yandexcloud.net/ MLFLOW_TRACKING_URI=http://<внутренний_IP-адрес_виртуальной_машины>:8000
-
-
Укажите данные, которые будут использоваться библиотекой
boto3для доступа к S3:-
Создайте папку
.aws:mkdir ~/.aws -
Создайте файл
credentials:nano ~/.aws/credentials -
Добавьте в него следующие строки, подставив идентификатор и значение статического ключа:
[default] aws_access_key_id=<идентификатор_статического_ключа> aws_secret_access_key=<секретный_ключ>
-
-
Запустите MLFlow Tracking Server, подставив данные вашего кластера:
mlflow server --backend-store-uri postgresql://<имя_пользователя>:<пароль>@<хост>:6432/db1?sslmode=verify-full --default-artifact-root s3://mlflow-bucket/artifacts -h 0.0.0.0 -p 8000Проверить подключение к MLFlow можно по ссылке
http://<публичный_IP-адрес_виртуальной_машины>:8000.
Включите автозапуск MLFlow
Чтобы MLFlow автоматически запускался после перезагрузки виртуальной машины, нужно сделать его службой Systemd.
-
Создайте директории для хранения логов и ошибок:
mkdir ~/mlflow_logs/ mkdir ~/mlflow_errors/ -
Создайте файл
mlflow-tracking.service:sudo nano /etc/systemd/system/mlflow-tracking.service -
Добавьте в него следующие строки, подставив свои данные:
[Unit] Description=MLflow Tracking Server After=network.target [Service] Environment=MLFLOW_S3_ENDPOINT_URL=https://storage.yandexcloud.net/ Restart=on-failure RestartSec=30 StandardOutput=file:/home/<имя_пользователя_ВМ>/mlflow_logs/stdout.log StandardError=file:/home/<имя_пользователя_ВМ>/mlflow_errors/stderr.log User=<имя_пользователя_ВМ> ExecStart=/bin/bash -c 'PATH=/home/<имя_пользователя_ВМ>/anaconda3/envs/mlflow_env/bin/:$PATH exec mlflow server --backend-store-uri postgresql://<имя_пользователя_БД>:<пароль>@<хост>:6432/db1?sslmode=verify-full --default-artifact-root s3://mlflow-bucket/artifacts -h 0.0.0.0 -p 8000' [Install] WantedBy=multi-user.targetГде:
<имя_пользователя_ВМ>— имя учетной записи пользователя ВМ;<имя_пользователя_БД>— имя пользователя, указанное при создании кластера БД.
-
Запустите сервис и активируйте автозагрузку при старте системы:
sudo systemctl daemon-reload sudo systemctl enable mlflow-tracking sudo systemctl start mlflow-tracking sudo systemctl status mlflow-tracking
Создайте секреты
-
Выберите нужный проект в своем сообществе или на главной странице DataSphere во вкладке Недавние проекты.
- В блоке Ресурсы проекта нажмите Секрет.
- Нажмите Создать.
- В поле Имя задайте имя секрета —
MLFLOW_S3_ENDPOINT_URL. - В поле Значение вставьте адрес —
https://storage.yandexcloud.net/. - Нажмите Создать.
- Создайте еще три секрета:
MLFLOW_TRACKING_URIсо значениемhttp://<внутренний_IP-адрес_виртуальной_машины>:8000;AWS_ACCESS_KEY_IDс идентификатором статического ключа;AWS_SECRET_ACCESS_KEYсо значением статического ключа.
Обучите модель
В примере используется набор данных для прогнозирования качества вина на основе количественных характеристик, таких как кислотность, водородный показатель, остаточный сахар и так далее. Чтобы обучить модель, скопируйте код в ячейки ноутбука.
-
Откройте проект DataSphere:
-
Выберите нужный проект в своем сообществе или на главной странице DataSphere во вкладке Недавние проекты.
- Нажмите кнопку Открыть проект в JupyterLab и дождитесь окончания загрузки.
- Откройте вкладку с ноутбуком.
-
-
Установите необходимые модули:
%pip install mlflow -
Импортируйте необходимые библиотеки:
import os import warnings import sys import pandas as pd import numpy as np from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score from sklearn.model_selection import train_test_split from sklearn.linear_model import ElasticNet from urllib.parse import urlparse import mlflow import mlflow.sklearn from mlflow.models import infer_signature import logging -
Создайте эксперимент в MLFlow:
mlflow.set_experiment("my_first_experiment") -
Создайте функцию оценки качества прогноза:
def eval_metrics(actual, pred): rmse = np.sqrt(mean_squared_error(actual, pred)) mae = mean_absolute_error(actual, pred) r2 = r2_score(actual, pred) return rmse, mae, r2 -
Подготовьте данные, обучите модель и зарегистрируйте ее в MLflow:
logging.basicConfig(level=logging.WARN) logger = logging.getLogger(__name__) warnings.filterwarnings("ignore") np.random.seed(40) # Загружаем датасет для оценки качества вина csv_url = ( "https://raw.githubusercontent.com/mlflow/mlflow/master/tests/datasets/winequality-red.csv" ) try: data = pd.read_csv(csv_url, sep=";") except Exception as e: logger.exception( "Unable to download training & test CSV, check your internet connection. Error: %s", e ) # Разделяем датасет на обучающую и тестовую выборку train, test = train_test_split(data) # Выделяем целевую переменную и переменные, используемые для прогноза train_x = train.drop(["quality"], axis=1) test_x = test.drop(["quality"], axis=1) train_y = train[["quality"]] test_y = test[["quality"]] alpha = 0.5 l1_ratio = 0.5 # Создаем запуск в mlflow with mlflow.start_run(): # Создаем и обучаем модель ElasticNet lr = ElasticNet(alpha=alpha, l1_ratio=l1_ratio, random_state=42) lr.fit(train_x, train_y) # Делаем прогнозы качества на тестовой выборке predicted_qualities = lr.predict(test_x) (rmse, mae, r2) = eval_metrics(test_y, predicted_qualities) print("Elasticnet model (alpha={:f}, l1_ratio={:f}):".format(alpha, l1_ratio)) print(" RMSE: %s" % rmse) print(" MAE: %s" % mae) print(" R2: %s" % r2) # Логируем информацию о гиперпараметрах и метриках качества в MLflow mlflow.log_param("alpha", alpha) mlflow.log_param("l1_ratio", l1_ratio) mlflow.log_metric("rmse", rmse) mlflow.log_metric("r2", r2) mlflow.log_metric("mae", mae) predictions = lr.predict(train_x) signature = infer_signature(train_x, predictions) tracking_url_type_store = urlparse(mlflow.get_tracking_uri()).scheme # Регистрируем модель в MLflow if tracking_url_type_store != "file": mlflow.sklearn.log_model( lr, "model", registered_model_name="ElasticnetWineModel", signature=signature ) else: mlflow.sklearn.log_model(lr, "model", signature=signature)Проверить результат можно по ссылке
http://<публичный_IP-адрес_виртуальной_машины>:8000.
Как удалить созданные ресурсы
Чтобы перестать платить за созданные ресурсы:
- удалите виртуальную машину;
- удалите кластер базы данных;
- удалите объекты из бакета;
- удалите бакет;
- удалите проект.