Объединение данных Yandex DataLens
Yandex DataLens использует подключение, чтобы получить данные из источника (БД, CSV, Metrica и т.д.). На основе предоставленных подключением данных можно создавать датасеты, чарты и селекторы. Если в источнике доступно несколько таблиц, вы можете объединять их для получения необходимого набора данных. Связать данные из разных датасетов можно на уровне чарта или через связь селекторов.
Способы объединения данных
Вы можете воспользоваться различными вариантами объединения данных:
На уровне датасета
Чтобы объединить данные на уровне датасета, вы можете добавить таблицы на рабочую область или написать SQL-запрос.
Важно
Нельзя объединить данные из разных источников на уровне одного датасета.
Добавление таблиц
В интерфейсе создания датасета можно объединять данные, перетаскивая таблицы на рабочую область и настраивая связи между ними через оператор JOIN. Пример объединения данных с помощью добавления таблиц смотрите в сценарии.
Примечание
При объединении данных из нескольких таблиц в датасете появляются дубликаты полей, по которым устанавливается связь. Их можно удалить вручную из списка полей датасета. Также можно описать датасет с помощью SQL-запроса, исключив в нем повторы полей в результирующем наборе.
SQL-запрос
В датасете можно добавить произвольный SQL-запрос к источнику данных. Текст запроса при обращении к источнику исполняется в виде подзапроса. Результат запроса можно использовать как итоговый набор данных датасета или объединить с другими таблицами источника через интерфейс.
На уровне чарта
DataLens позволяет объединить данные на уровне чарта. Для объединения данных на уровне чарта вы можете использовать QL-чарт или мультидатасетные чарты.
QL-чарт
QL-чарты — чарты, созданные на основе подключения, если источник подключения — БД. При выполнении SQL-запроса отдельный объект Датасет не создается, он генерируется сразу и отображается на панели превью. Подробнее в инструкции Создание QL-чарта в Yandex DataLens.
Мультидатасетные чарты
Мультидатасетные чарты — чарты, которые отображают данные из разных датасетов. Запросы для каждого датасета отрабатываются независимо друг от друга. Подробнее в инструкции Создание мультидатасетного чарта.
На уровне связей селекторов
Можно добавить на дашборд селектор, который влияет на результаты запросов в связанных с ним виджетах:
- на дашборде селекторы и чарты, построенные на основе одного датасета, связываются автоматически;
- селекторы и чарты, построенные на основе разных датасетов, можно связать вручную с помощью алиасов.
Перед созданием связи убедитесь, что поле, по которому фильтрует селектор, присутствует в датасете, на основе которого построен чарт. В противном случае связь работать не будет. Подробнее в инструкции Создание алиаса в Yandex DataLens.
Оптимизация данных при объединении таблиц
В некоторых чартах, построенных на основе датасета с объединенными таблицами, могут использоваться поля только из одной таблицы. В этом случае DataLens оптимизирует запрос к источнику. Оператор JOIN не применяется, и запрос возвращает данные только из одной таблицы без фильтрации по другим. Это позволяет уменьшить объем запрашиваемых данных и сократить время выполнения запроса. Но при этом данные, которые возвращает оптимизированный запрос, могут отличаться от ожидаемых.
Оптимизация применяется при следующих условиях:
- в настройках связи таблиц включена опция Оптимизировать связь;
- в чарте используются поля только одной из связанных таблиц;
- поля из других таблиц не находятся ни в одной из секций чарта;
- поля из других таблиц не используются в вычисляемых полях чарта.
Примечание
Оптимизация не работает, если датасет описан через SQL-запрос к источнику.
Рассмотрим оптимизацию на примере разных датасетов для источника с таблицами:
Сотрудники
| id | name | department_id |
|---|---|---|
| 1 | Иванов | 2 |
| 2 | Петров | 4 |
| 3 | Сидоров | 1 |
| 4 | Степанов | 1 |
| 5 | Соколов | |
| 6 | Орлова | 3 |
| 7 | Шишкина | 3 |
| 8 | Семенов | |
| 9 | Антонова | 3 |
| 10 | Сергеев | 4 |
Отделы
| id | name |
|---|---|
| 1 | Логистика |
| 2 | ИТ |
| 3 | Бухгалтерия |
| 4 | СБ |
Премии
| employee_id | bonus |
|---|---|
| 1 | 35 000 |
| 2 | 40 000 |
| 5 | 28 000 |
| 7 | 30 000 |
| 9 | 50 000 |
Квалификация
| employee_id | category |
|---|---|
| 2 | Категория 1 |
| 4 | Категория 1 |
| 5 | Категория 2 |
| 6 | Категория 3 |
| 7 | Категория 3 |
| 8 | Категория 2 |
| 10 | Категория 1 |
Примеры
INNER JOIN двух таблиц
Датасет построен из таблиц Сотрудники и Отделы, объединенных оператором INNER JOIN.

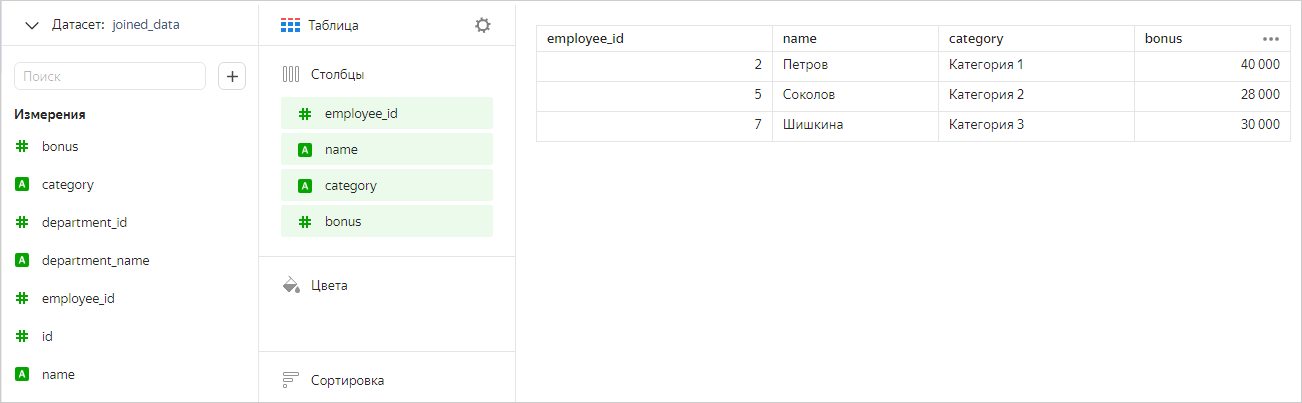
В результате объединения в датасете содержатся только общие строки из двух таблиц. Построим чарт, содержащий поля из обеих таблиц.
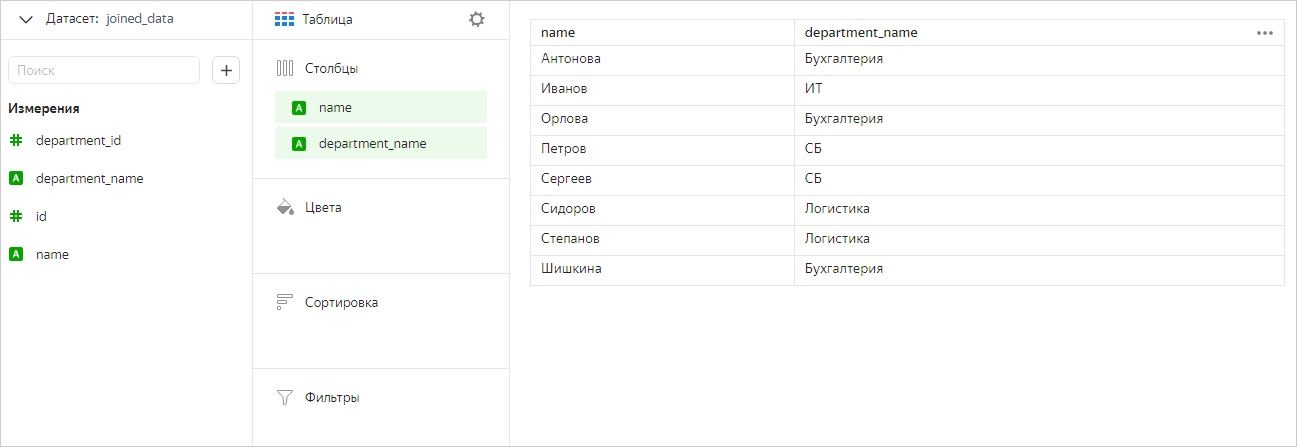
Теперь построим чарт только с полями таблицы Сотрудники. В этом случае DataLens не применяет оператор JOIN и работает только с этой таблицей. В чарте мы видим все значения из таблицы Сотрудники, а не только те, которые пересекаются с таблицей Отделы.
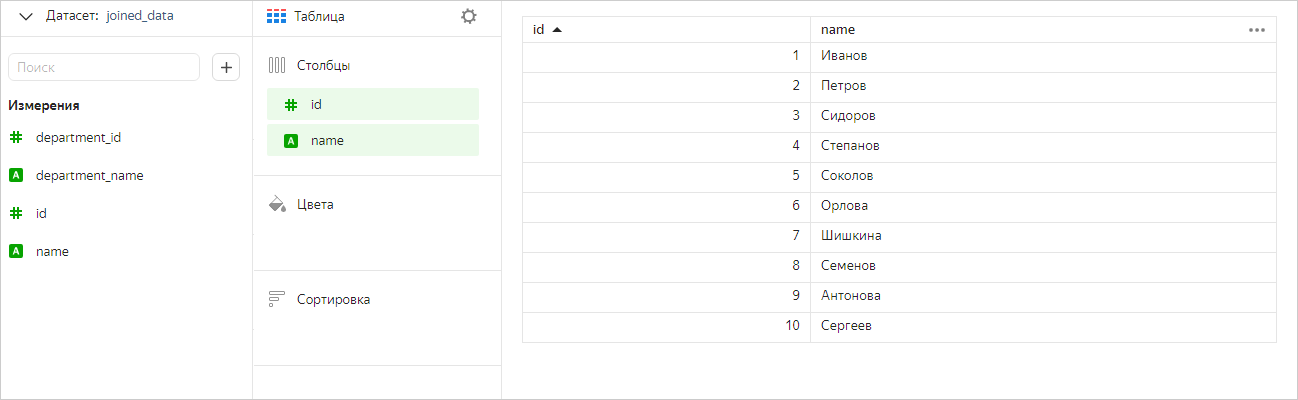
LEFT/RIGHT JOIN двух таблиц
Датасет построен на основе таблиц Премии и Сотрудники, объединенных оператором LEFT JOIN. Таблица Премии используется целиком, а из таблицы Сотрудники выбираются только те значения, которые есть в Премии.

Построим чарт, содержащий поля из обеих таблиц.
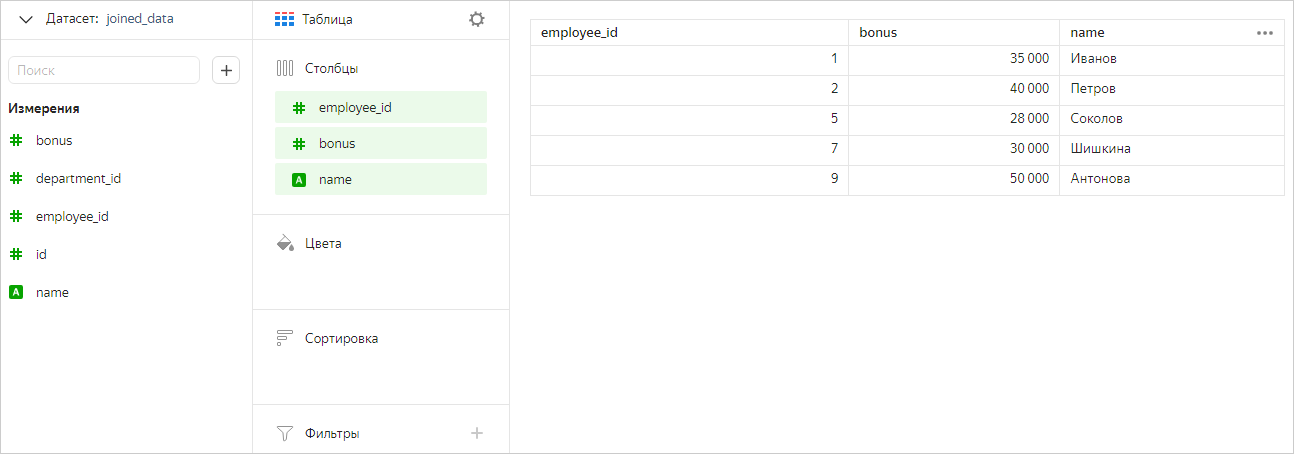
Теперь оставим в чарте только поля из таблицы Сотрудники. В этом случае мы увидим в чарте все значения из этой таблицы (без фильтрации по таблице Премии).
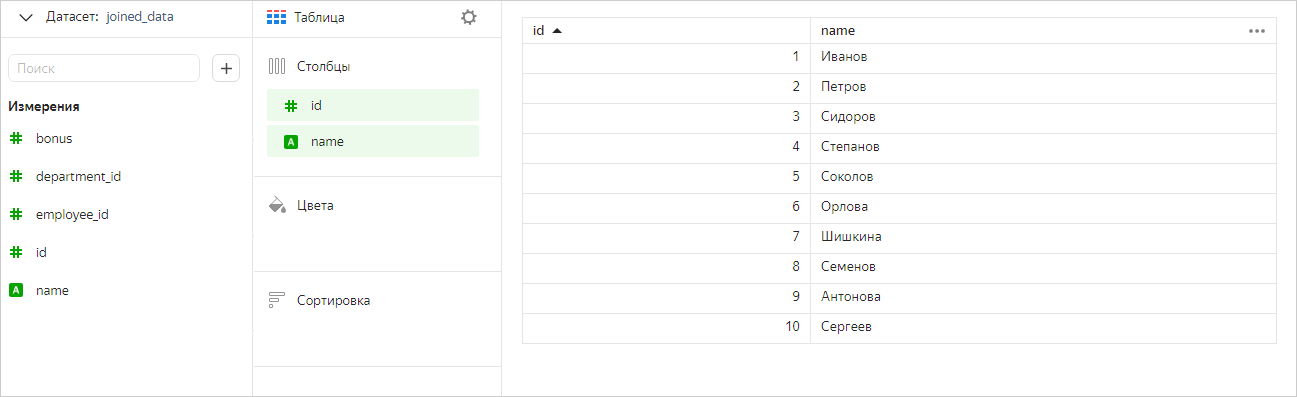
Так же работает оптимизация и для оператора RIGHT JOIN.
INNER JOIN трех таблиц
Датасет построен на основе трех таблиц:
- первая таблица (
Отделы) объединена операторомINNER JOINcо второй таблицей (Сотрудники); - вторая таблица (
Сотрудники) объединена операторомINNER JOINc третьей таблицей (Премии).

Построим чарт, содержащий поля из всех таблиц.
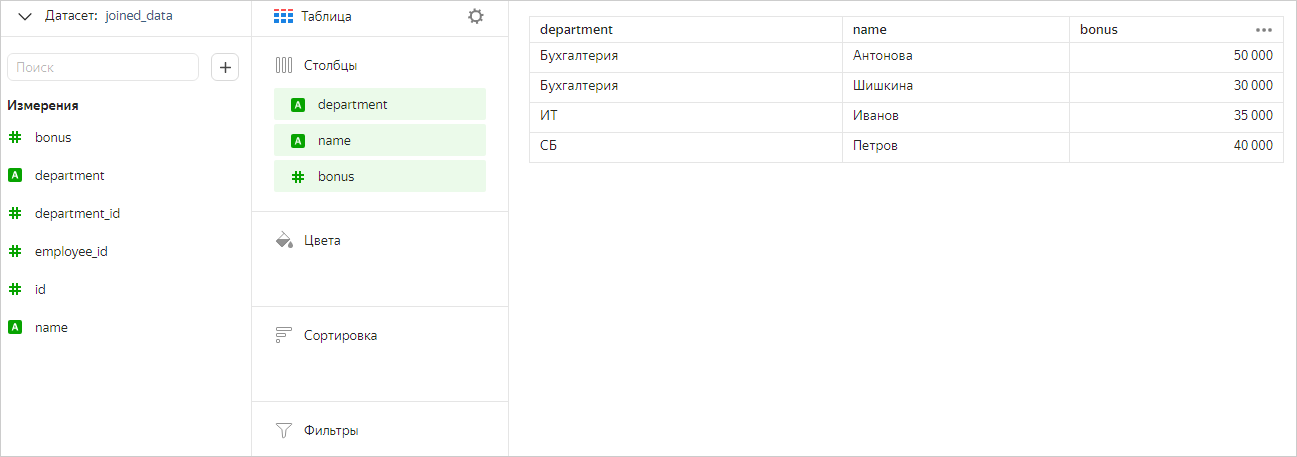
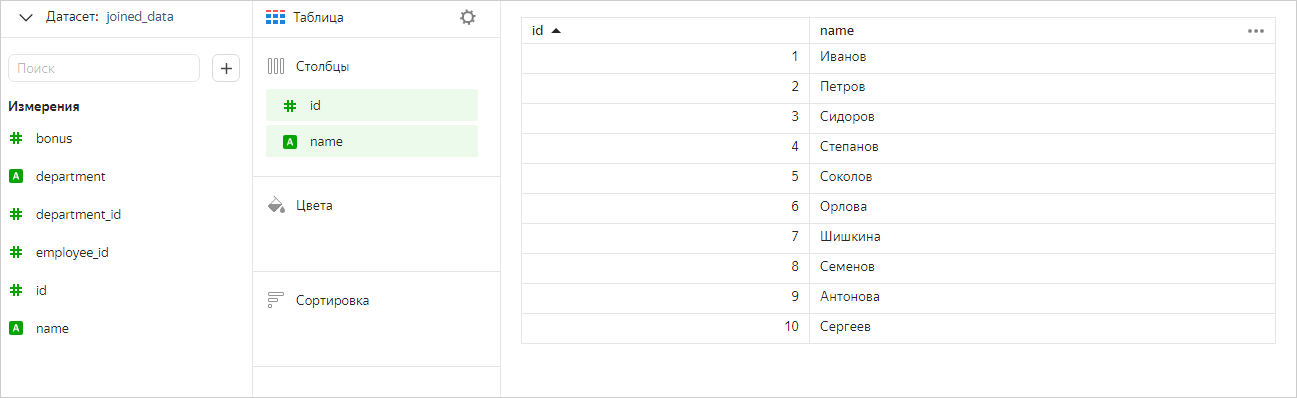
Теперь оставим в чарте только поля из таблицы Сотрудники. В этом случае мы увидим в чарте все значения из этой таблицы (без фильтрации по таблицам Премии и Отделы).
Добавим в чарт поля только из первой (Отделы) и третьей (Премии) таблицы. Явной связи между этими таблицами нет, но каждая из них связана с таблицей Сотрудники. Поэтому DataLens не оптимизирует запрос к источнику. В этом случае мы увидим в чарте значения из всех трех таблиц с учетом фильтрации.
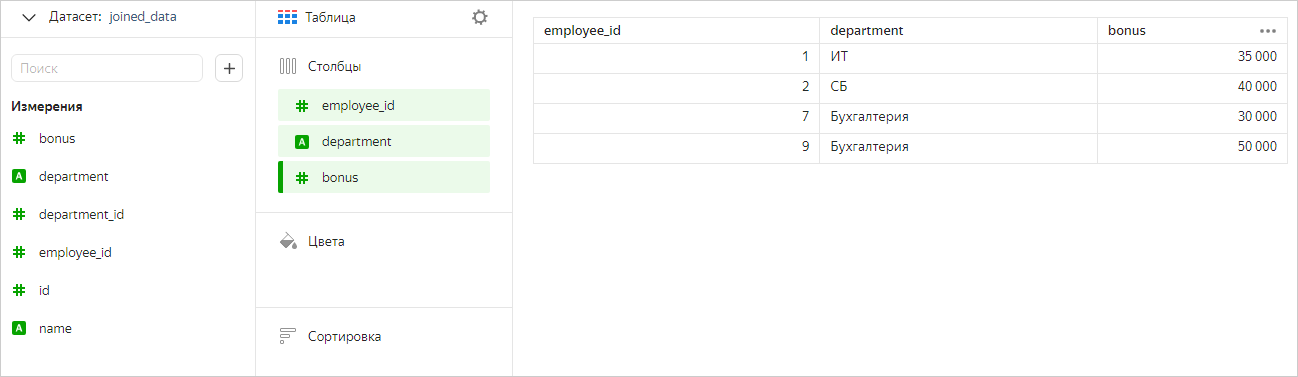
INNER JOIN одной таблицы с двумя другими
Датасет построен на основе трех таблиц:
- первая таблица (
Сотрудники) объединена операторомINNER JOINcо второй таблицей (Отделы); - первая таблица (
Сотрудники) объединена операторомINNER JOINc третьей таблицей (Премии).

Построим чарт, содержащий поля из всех таблиц.
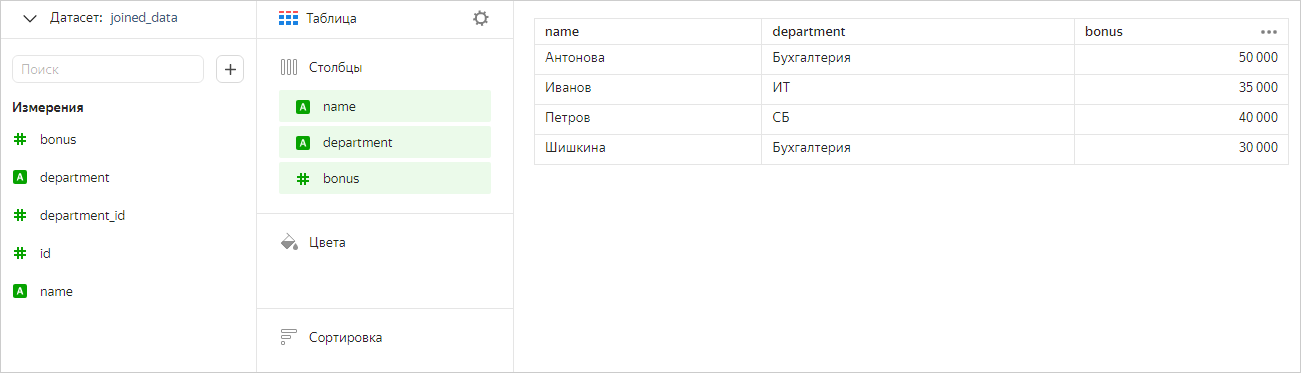
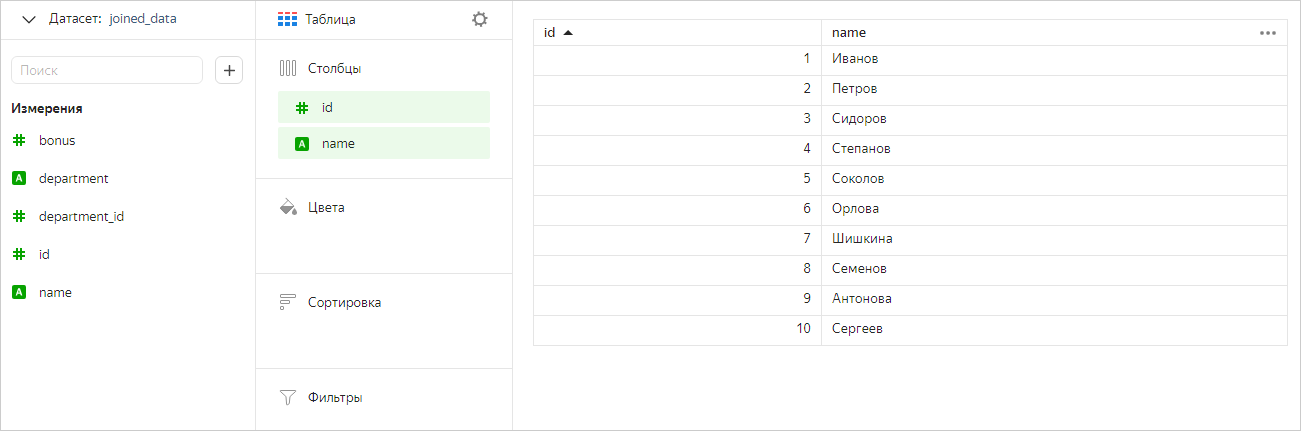
Теперь оставим в чарте только поля из таблицы Сотрудники. В этом случае мы увидим в чарте все значения из этой таблицы (без фильтрации по таблицам Отделы и Премии).
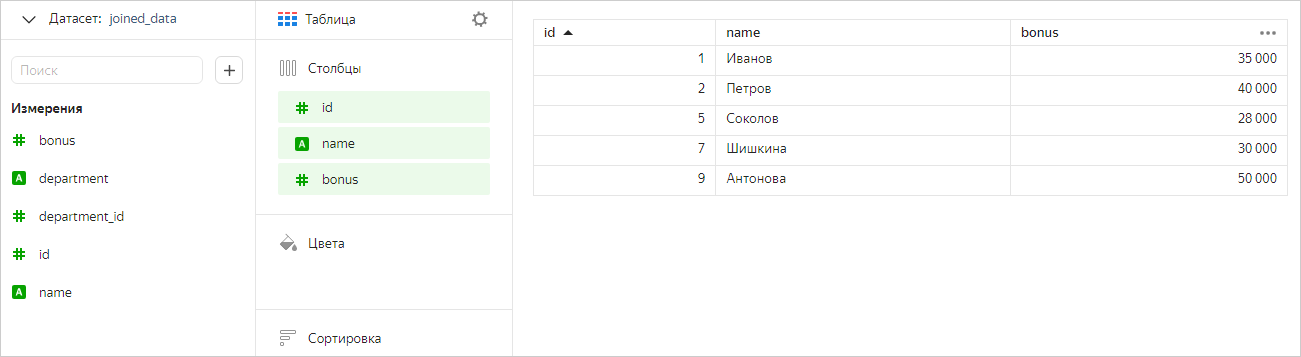
Добавим в чарт поля только из первой (Сотрудники) и третьей (Премии) таблицы. В этом случае мы увидим в чарте общие значения из этих таблиц (без фильтрации по таблице Отделы).
INNER JOIN четырех таблиц
Датасет построен на основе четырех таблиц:
- первая таблица (
Квалификация) объединена операторомINNER JOINcо второй таблицей (Премии); - первая таблица (
Квалификация) объединена операторомINNER JOINc третьей таблицей (Сотрудники); - третья таблица (
Сотрудники) объединена операторомINNER JOINc четвертой таблицей (Отделы).

Построим чарт, содержащий поля из всех таблиц.
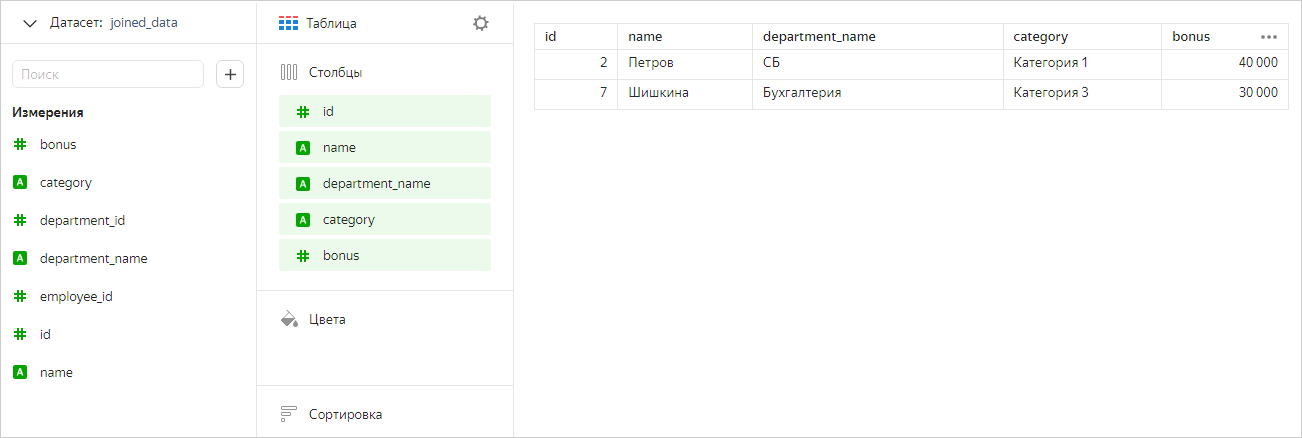
Теперь оставим в чарте только поля из таблицы Квалификация. В этом случае мы увидим в чарте все значения из этой таблицы (без фильтрации по остальным таблицам).
Если использовать в чарте только пару связанных между собой таблиц (первую и вторую, первую и третью, третью и четвертую), то в чарте отобразятся общие значения из этих таблиц (без фильтрации по остальным таблицам). Например, добавим в чарт поля только из первой (Квалификация) и второй (Премии) таблицы.