Интеграция с сервисом Yandex DataSphere
Вы можете использовать в проектах Yandex DataSphere кластеры Apache Spark™, развернутые в сервисе Yandex Data Processing. Чтобы в DataSphere настроить интеграцию с сервисом Yandex Data Processing:
- Подготовьте инфраструктуру.
- Настройте проект DataSphere.
- Создайте бакет.
- Создайте кластер Yandex Data Processing.
- Запустите вычисления.
Если созданные ресурсы вам больше не нужны, удалите их.
Перед началом работы
Перед началом работы нужно зарегистрироваться в Yandex Cloud, настроить сообщество и привязать к нему платежный аккаунт:
- На главной странице DataSphere нажмите Попробовать бесплатно и выберите аккаунт для входа — Яндекс ID или рабочий аккаунт в федерации (SSO).
- Выберите организацию Yandex Identity Hub, в которой вы будете работать в Yandex Cloud.
- Создайте сообщество.
- Привяжите платежный аккаунт к сообществу DataSphere, в котором вы будете работать. Убедитесь, что у вас подключен платежный аккаунт, и он находится в статусе
ACTIVEилиTRIAL_ACTIVE. Если платежного аккаунта нет, создайте его в интерфейсе DataSphere.
Войдите в консоль управления Yandex Cloud и выберите организацию, в которой вы работаете с DataSphere. На странице Yandex Cloud Billing убедитесь, что у вас подключен платежный аккаунт.
Если у вас есть активный платежный аккаунт, на странице облака вы можете создать или выбрать каталог, в котором будет работать ваша инфраструктура.
Примечание
Если вы работаете с Yandex Cloud через федерацию удостоверений, вам может быть недоступна платежная информация. В этом случае обратитесь к администратору вашей организации в Yandex Cloud.
Необходимые платные ресурсы
- Кластер Yandex Data Processing: использование вычислительных ресурсов с наценкой за сервис Yandex Data Processing, использование сетевых дисков, получение и хранение логов, объем исходящего трафика (тарифы Yandex Data Processing).
- NAT-шлюз: почасовое использование шлюза и исходящий через него трафик (тарифы Yandex Virtual Private Cloud).
- Бакет Yandex Object Storage: использование хранилища и выполнение операций с данными (тарифы Object Storage).
Подготовьте инфраструктуру
Создайте каталог и сеть
Создайте каталог, в котором будет работать ваш кластер Yandex Data Processing.
- В консоли управления выберите облако и нажмите Создать каталог.
- Введите имя каталога, например
data-folder. - Отключите опцию Создать сеть по умолчанию, чтобы создать сеть и подсеть вручную.
- Нажмите Создать.
Подробнее об облаках и каталогах.
Создайте сеть
Создайте сеть, в которой будет работать кластер Yandex Data Processing.
- В консоли управления перейдите в каталог
data-folder, созданный ранее. - В списке сервисов выберите Virtual Private Cloud.
- В правом верхнем углу нажмите Создать сеть.
- В поле Имя укажите имя сети
data-network. - Отключите опцию Создать подсети.
- Нажмите Создать сеть.
Создайте подсеть
- В каталоге
data-folderперейдите в сервис Virtual Private Cloud. - Выберите облачную сеть
data-network. - Нажмите Создать подсеть.
- Укажите имя подсети
data-subnet. - Выберите зону доступности
ru-central1-a. - Введите CIDR подсети, например
10.1.1.0/24. - Нажмите Создать подсеть.
Создайте NAT-шлюз для доступа в интернет
- В каталоге
data-folderперейдите в сервис Virtual Private Cloud. - На панели слева выберите Шлюзы.
- Нажмите Создать и задайте настройки шлюза:
- Введите имя шлюза, например
nat-for-cluster. - Выберите Тип шлюза — NAT-шлюз.
- Нажмите Сохранить.
- Введите имя шлюза, например
- На панели слева выберите Таблицы маршрутизации.
- Нажмите Создать и введите параметры таблицы маршрутизации:
- Введите имя, например
route-table. - Выберите сеть
data-network. - Нажмите Добавить маршрут.
- В открывшемся окне в поле Next hop выберите Шлюз.
- В поле Шлюз выберите созданный NAT-шлюз. Префикс назначения заполнится автоматически.
- Нажмите Добавить.
- Введите имя, например
- Нажмите Создать таблицу маршрутизации.
Затем привяжите таблицу маршрутизации к подсети data-subnet, чтобы направить трафик из нее через NAT-шлюз:
- На панели слева выберите Подсети.
- В строке подсети
data-subnetнажмите . - В открывшемся меню выберите пункт Привязать таблицу маршрутизации.
- В открывшемся окне выберите созданную таблицу в списке.
- Нажмите Привязать.
Создайте сервисный аккаунт для кластера Yandex Data Processing
-
Перейдите в каталог
data-folder. -
Перейдите в сервис Identity and Access Management.
-
Нажмите кнопку Создать сервисный аккаунт.
-
Введите имя сервисного аккаунта, например
sa-for-data-proc. -
Нажмите Добавить роль и назначьте сервисному аккаунту роли:
dataproc.agent— для создания и использования кластеров Yandex Data Processing.dataproc.provisioner— для автомасштабирования подкластеров.dataproc.user— для доступа к кластерам Yandex Data Processing от имени сервисного агента.vpc.user— для работы с сетью кластера Yandex Data Processing.iam.serviceAccounts.user— для создания ресурсов в каталоге от имени сервисного аккаунта.
-
Нажмите Создать.
Сгенерируйте пару ключей SSH
Для безопасного подключения к хостам кластера Yandex Data Processing потребуются SSH-ключи. Если у вас уже есть сгенерированные SSH-ключи, вы можете пропустить этот шаг.
Как сгенерировать пару ключей SSH
-
Откройте терминал.
-
Создайте новый ключ с помощью команды
ssh-keygen:ssh-keygen -t ed25519 -C "<опциональный_комментарий>"Вы можете передать в параметре
-Cпустую строку, чтобы не добавлять комментарий, или не указывать параметр-Cвообще — в таком случае будет добавлен комментарий по умолчанию.После выполнения команды вам будет предложено указать имя и путь к файлам с ключами, а также ввести пароль для закрытого ключа. Если задать только имя, пара ключей будет создана в текущей директории. Открытый ключ будет сохранен в файле с расширением
.pub, закрытый ключ — в файле без расширения.По умолчанию команда предлагает сохранить ключ под именем
id_ed25519в директории/home/<имя_пользователя>/.ssh. Если в этой директории уже есть SSH-ключ с именемid_ed25519, вы можете случайно перезаписать его и потерять доступ к ресурсам, в которых он используется. Поэтому рекомендуется использовать уникальные имена для всех SSH-ключей.
Если у вас еще не установлен OpenSSH, установите его по инструкции.
-
Запустите
cmd.exeилиpowershell.exe(предварительно обновите PowerShell). -
Создайте новый ключ с помощью команды
ssh-keygen:ssh-keygen -t ed25519 -C "<опциональный_комментарий>"Вы можете передать в параметре
-Cпустую строку, чтобы не добавлять комментарий, или не указывать параметр-Cвообще — в таком случае будет добавлен комментарий по умолчанию.После выполнения команды вам будет предложено указать имя и путь к файлам с ключами, а также ввести пароль для закрытого ключа. Если задать только имя, пара ключей будет создана в текущей директории. Открытый ключ будет сохранен в файле с расширением
.pub, закрытый ключ — в файле без расширения.По умолчанию команда предлагает сохранить ключ под именем
id_ed25519в папкуC:\Users\<имя_пользователя>/.ssh. Если в этой директории уже есть SSH-ключ с именемid_ed25519, вы можете случайно перезаписать его и потерять доступ к ресурсам, в которых он используется. Поэтому рекомендуется использовать уникальные имена для всех SSH-ключей.
Создайте ключи с помощью приложения PuTTY:
-
Скачайте и установите PuTTY.
-
Добавьте папку с PuTTY в переменную
PATH:- Нажмите кнопку Пуск и в строке поиска Windows введите Изменение системных переменных среды.
- Справа снизу нажмите кнопку Переменные среды....
- В открывшемся окне найдите параметр
PATHи нажмите Изменить. - Добавьте путь к папке в список.
- Нажмите кнопку ОК.
-
Запустите приложение PuTTYgen.
-
В качестве типа генерируемой пары выберите EdDSA. Нажмите Generate и поводите курсором в поле выше до тех пор, пока не закончится создание ключа.
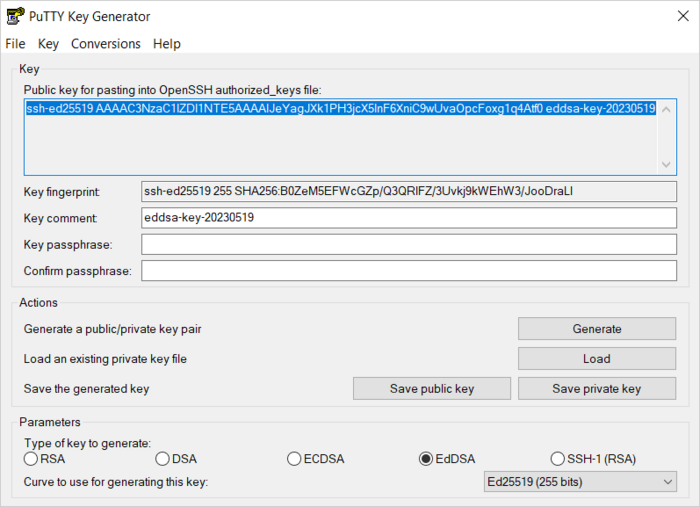
-
В поле Key passphrase введите надежный пароль. Повторно введите его в поле ниже.
-
Нажмите кнопку Save private key и сохраните закрытый ключ. Никому не сообщайте ключевую фразу от него.
-
Нажмите кнопку Save public key и сохраните открытый ключ в файле
<имя_ключа>.pub.
Важно
Надежно сохраните закрытый ключ: без него подключиться к ВМ будет невозможно.
Настройте DataSphere
Чтобы работать с кластерами Yandex Data Processing в DataSphere, создайте и настройте проект.
Создайте проект
- Откройте главную страницу DataSphere.
- На панели слева выберите Сообщества.
- Выберите сообщество, в котором вы хотите создать проект.
- На странице сообщества нажмите кнопку Создать проект.
- В открывшемся окне укажите имя и (опционально) описание проекта.
- Нажмите кнопку Создать.
Измените настройки проекта
-
Перейдите на вкладку Настройки.
-
В блоке Расширенные настройки нажмите кнопку Редактировать.
-
Укажите параметры:
- Каталог по умолчанию —
data-folder. - Сервисный аккаунт —
sa-for-data-proc. - Подсеть —
data-subnet. - Группу безопасности, если они используются в вашей организации.
- Каталог по умолчанию —
-
Нажмите Сохранить.
Измените настройки сообщества
Чтобы настроить подключение к кластерам Yandex Data Processing:
- Выберите сообщество, в котором вы создали проект.
- Перейдите на вкладку Настройки.
- В блоке Сервисный агент нажмите Добавить сервисный аккаунт.
- В открывшемся окне выберите созданный ранее сервисный аккаунт и нажмите Добавить.
- В блоке Кластеры Spark нажмите Добавить сервисный аккаунт и выберите созданный ранее сервисный аккаунт.
Создайте бакет
- В консоли управления выберите каталог, в котором вы хотите создать бакет.
- Перейдите в сервис Object Storage.
- Нажмите кнопку Создать бакет.
- В поле Имя укажите имя бакета.
- В полях Чтение объектов, Чтение списка объектов и Чтение настроек выберите С авторизацией.
- Нажмите кнопку Создать бакет.
Создайте кластер Yandex Data Processing
Перед созданием кластера убедитесь, что в вашем облаке имеется достаточный суммарный объем SSD-дисков (по умолчанию для нового облака выделяется 200 ГБ).
Посмотреть имеющиеся у вас ресурсы можно в консоли управления в разделе Квоты.
-
В консоли управления выберите каталог, в котором нужно создать кластер.
-
Нажмите Создать ресурс и выберите Кластер Yandex Data Processing в выпадающем списке.
-
Введите имя кластера в поле Имя кластера. Имя кластера должно быть уникальным в рамках каталога.
-
В поле Окружение выберите
PRODUCTION. -
В поле Версия выберите
2.1. -
В поле Сервисы выберите:
LIVY,SPARK,YARNиHDFS. -
Вставьте в поле SSH-ключ публичную часть вашего SSH-ключа.
-
В поле Сервисный аккаунт выберите
sa-for-data-proc. -
В поле Зона доступности выберите
ru-central1-a. -
В поле Свойства задайте настройку для интеграции кластера с DataSphere:
livy:livy.spark.deploy-mode : clientПри необходимости задайте свойства Hadoop и его компонентов, например:
hdfs:dfs.replication : 2 hdfs:dfs.blocksize : 1073741824 spark:spark.driver.cores : 1 -
В поле Имя бакета выберите созданный бакет.
-
Выберите сеть
data-network. -
Включите опцию UI Proxy, чтобы получить доступ к веб-интерфейсам компонентов Yandex Data Processing.
-
Настройте подкластеры: не больше одного главного подкластера с управляющим хостом (обозначается как Мастер) и подкластеры для хранения данных или вычислений.
Примечание
Для проведения вычислений на кластерах у вас должен быть хотя бы один подкластер типа
ComputeилиData.Роли подкластеров (
ComputeиData) различаются тем, что наData-подкластерах можно разворачивать компоненты для хранения данных, а наCompute— компоненты обработки данных. Хранилище на подкластереComputeпредназначено только для временного хранения обрабатываемых файлов. -
Для каждого подкластера можно настроить:
- Количество хостов.
- Класс хостов — платформа и вычислительные ресурсы, доступные хосту.
- Размер и тип хранилища.
- Подсеть сети, в которой расположен кластер.
-
Для
Compute-подкластеров можно задать параметры автоматического масштабирования. -
После настройки всех подкластеров нажмите Создать кластер.
Yandex Data Processing запустит операцию создания кластера. После того как кластер перейдет в статус Running, вы можете подключиться к любому активному подкластеру с помощью указанного SSH-ключа.
Созданный кластер Yandex Data Processing появится в проекте DataSphere в разделе Ресурсы проекта ⟶ Yandex Data Processing ⟶ Доступные кластеры.
Запустите вычисления на кластере
-
Откройте проект DataSphere:
-
Выберите нужный проект в своем сообществе или на главной странице DataSphere во вкладке Недавние проекты.
- Нажмите кнопку Открыть проект в JupyterLab и дождитесь окончания загрузки.
- Откройте вкладку с ноутбуком.
-
-
В ячейку вставьте код для вычисления, например:
#!spark --cluster <имя_кластера> import random def inside(p): x, y = random.random(), random.random() return x*x + y*y < 1 NUM_SAMPLES = 1_000_000 count = sc.parallelize(range(0, NUM_SAMPLES)) \ .filter(inside).count() print("Pi is roughly %f" % (4.0 * count / NUM_SAMPLES))Где
#!spark --cluster <имя_кластера>— обязательная системная команда для запуска вычислений на кластере. -
Создайте еще одну ячейку и вставьте в нее код для записи данных в S3, указав имя бакета:
#!spark --cluster <имя_кластера> data = [[1, "tiger"], [2, "lion"], [3, "snow leopard"]] df = spark.createDataFrame(data, schema="id LONG, name STRING") df.repartition(1).write.option("header", True).mode("overwrite").csv("s3a://<имя_бакета>/test") -
Запустите все ячейки, выбрав в меню Run ⟶ Run All Cells.
-
В открывшемся окне Конфигурации ВМ ноутбука выберите конфигурацию ВМ и нажмите Выбрать.
Дождитесь запуска вычислений. Под ячейкой в процессе вычисления будут отображаться логи.
После этого файл появится в папке test бакета. Чтобы просматривать содержимое бакета в интерфейсе JupyterLab, создайте и активируйте в проекте коннектор S3.
Примечание
Чтобы получить из кластера Yandex Data Processing данные больше 100 МБ, используйте коннектор S3.
Подробнее о запуске вычислений на кластерах Yandex Data Processing в DataSphere смотрите в концепции.
Удалите созданные ресурсы
Важно
Используя кластер, развернутый в сервисе Yandex Data Processing, вы управляете его жизненным циклом самостоятельно. Кластер будет работать и тарифицироваться, пока вы его не выключите.
Некоторые ресурсы платные. Чтобы за них не списывалась плата, удалите ресурсы, которые вы больше не будете использовать: