Новый Yandex DataSphere — вышли за пределы JupyterLab®
Представляем обновленный Yandex DataSphere — наиболее продвинутое полноценное интегрированное рабочее место для дата-сайентиста.
22 сентября 2022 г.
15 минут чтения
На Yandex Scale мы объявили о новом Yandex DataSphere. Наша команда создала не просто новый интерфейс, а наиболее продвинутое полноценное интегрированное рабочее место для дата-сайентиста с возможностью сохранять и воспроизводить результаты исследований, вести командную работу, расширяя возможности стандартных для индустрии инструментов, таких как JupyterLab. Интерфейс проектировался на основании исследования пользовательского опыта и обратной связи от наших клиентов. В этой статье расскажем, почему это полноценный перезапуск сервиса для машинного обучения в Yandex Cloud.
Первая версия DataSphere
Первоначальным интерфейсом DataSphere был привычный для дата-сайентиста JupyterLab® — гибкий, имеющий множество плагинов, в том числе и в серверной части. Облачные мощности и понятный интерфейс позволили разработчикам быстро запустить DataSphere и развивать проект дальше. Например, добавить сохранения состояний, асинхронные и параллельные вычисления. Однако JupyterLab® создавался не как инструмент для работы в облаке, поэтому от него требовалась значительно большая функциональность. Для этого разработчики DataSphere стремились связать JupyterLab® с инфраструктурой облака и другими решениями, нужными дата-сайентисту.
Следующей стадией развития DataSphere стали контрольные точки, в которых сохранялись результаты работы дата-сайентиста с возможностью делиться ими и превращать их в готовые сервисы. Все члены команды теперь могли распределять роли, видеть вклад каждого и обсуждать результаты друг с другом, а возможно — и с более широким сообществом.
В какой-то момент разработчики DataSphere вышли за пределы JupyterLab®, и результатом стали новая версия и новый интерфейс сервиса с гораздо большими возможностями и иной логикой использования.
Новое рабочее место дата-сайентиста
Новый Yandex DataSphere — это полноценное рабочее место с инструментами для командной работы, в котором пользователи с разными ролями могут выполнять различные задачи, не мешая друг другу.
Наш сервис закрывает весь жизненный цикл ML-моделей для бизнеса:
Подготовка данных. Полноценная подготовка для того, чтобы разработчики самостоятельно создавали модели.
Разработка. Создание модели и её обучение на датасетах.
Эксплуатация. Превращение модели в самостоятельный сервис.
Теперь специалисту по машинному обучению не нужно каждый раз настраивать среду разработки и связывать между собой разрозненные инструменты. DataSphere учитывает все этапы работы, а возможности облачной инфраструктуры почти безграничны: хранение практически любого объёма данных в объектном хранилище, использование сетевых и вычислительных возможностей, распределённое обучение (Training as a Service) и т. д.
Что мы добавили
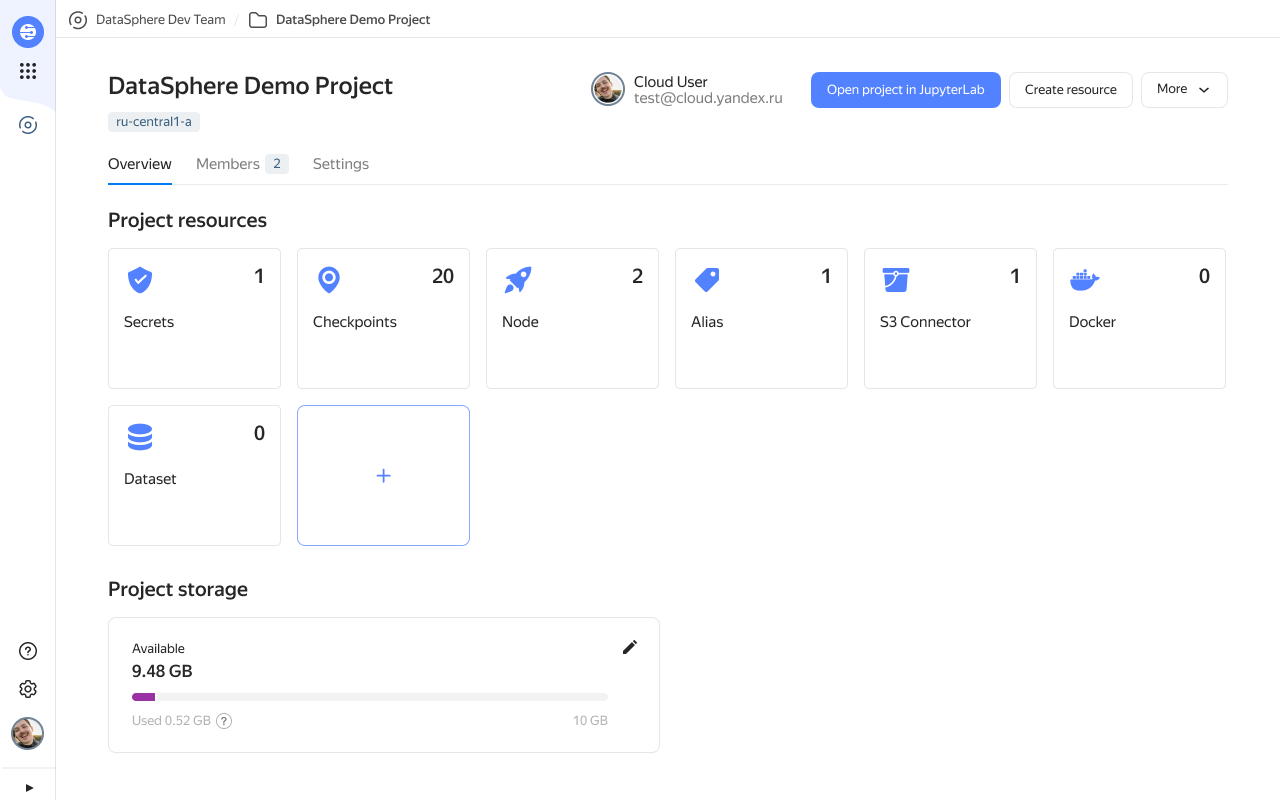
Проект. Это главная сущность, с которой работает дата-сайентист в новом интерфейсе. Проектом, его настройками, доступами и ресурсами (Docker-образами, нодами, датасетами и контрольными точками) можно управлять, не переходя в саму среду разработки. Контрольная точка стала полноценным ресурсом, в котором можно посмотреть многие подробности проектов, даже сохранённые переменные. Дата‑сайентист может сохранить свою контрольную точку и вернуться к своим вычислениям, когда ему будет удобно.
Евгений Левашов
Главный редактор Yandex Cloud. Пишет для IT-компаний с 2015 года, ведёт собственный блог и канал про технологии.
Интеграция с Yandex Data Proc. Сервис Yandex Data Proc помогает разворачивать кластеры Apache Hadoop® и Apache Spark™ в инфраструктуре Yandex Cloud. Вы сами определяете размер кластера, мощность узлов и набор сервисов Apache. В новой версии DataSphere мы добавили удобную интеграцию с кластерами Data Proc, которые обеспечивают расчёт в MapReduce-парадигме, что важно при подготовке данных и в работе дата-инженеров или аналитиков. Также появилась возможность быстро обмениваться внутри проекта датасетами и другими артефактами в объектном хранилище. Внешние источники данных интегрированы с помощью интуитивно понятных виджетов.
Эксплуатация моделей — быстрый переход в инференс. После обучения модели вы можете нажатием нескольких кнопок быстро выводить её в продакшн, чтобы начать получать пользу для бизнеса. Также можно создавать сервисы на основе полученных моделей из контрольной точки и из Docker-образа. В новой версии DataSphere поддерживаются алиасы к сервисам, которые позволяют заменять версии моделей бесшовно и без остановки уже работающего сервиса.
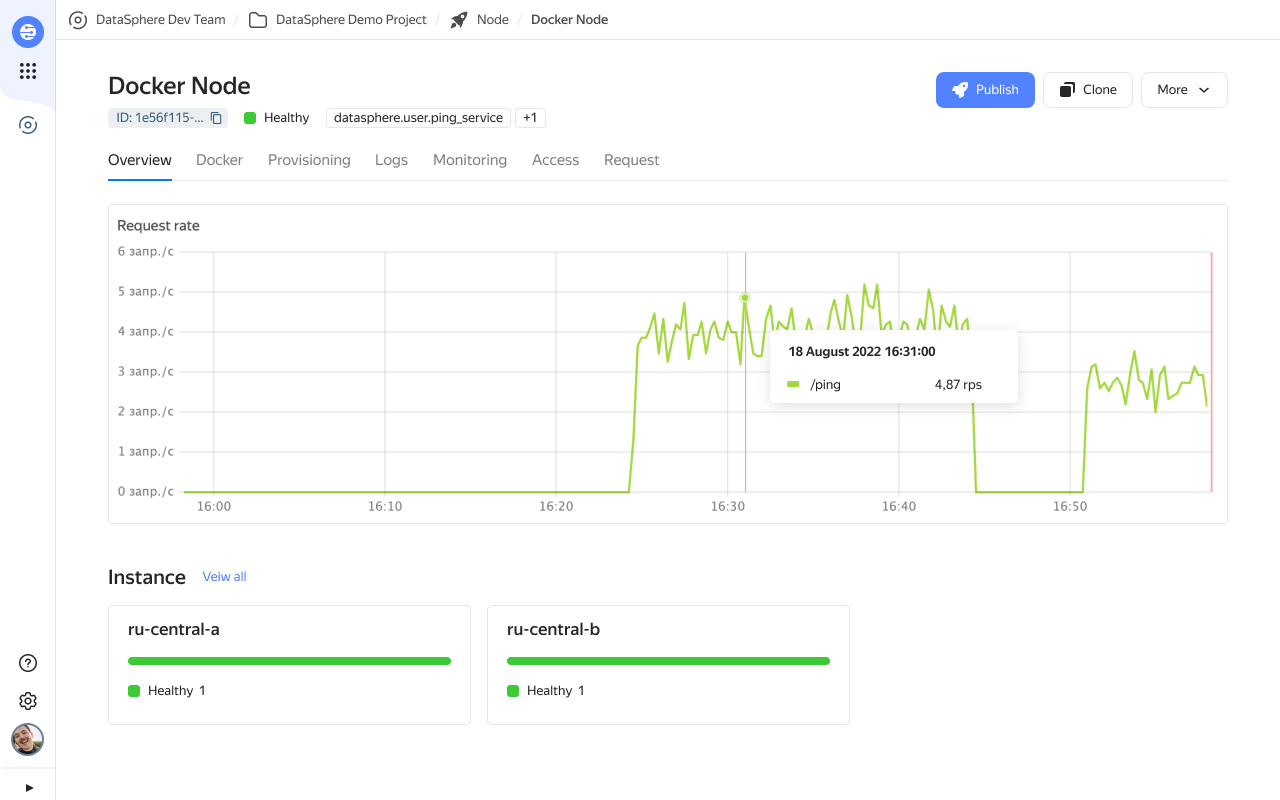
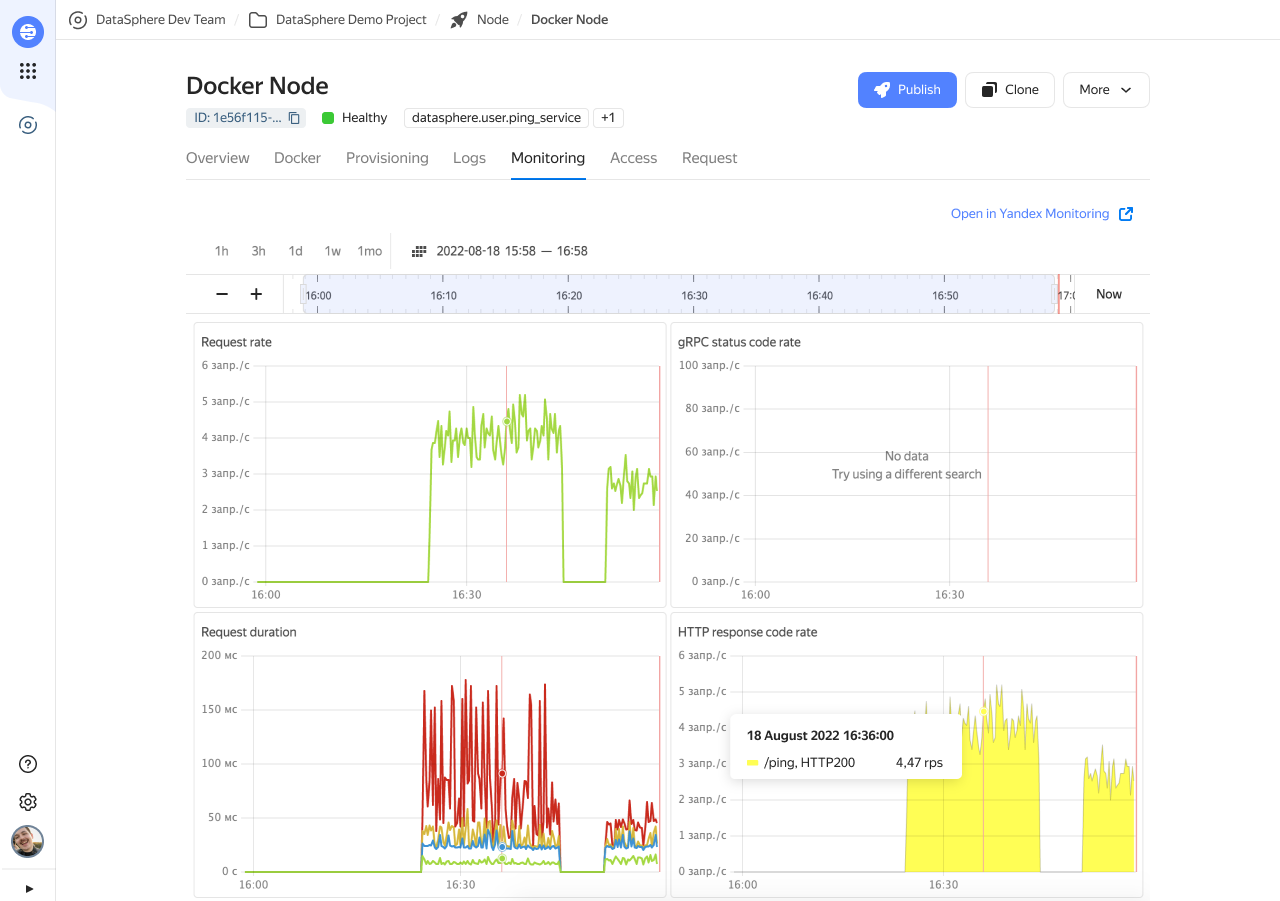
Дашборд здоровья сервиса. После перехода в инференс главный инструмент эксплуатации в новом интерфейсе — дашборд здоровья сервиса. Он отслеживает состояние уже созданных сервисов, показывает график текущей нагрузки, состояние серверов и занятые ресурсы. Более подробно изучить работу каждой машины можно в логах созданного сервиса.
Сообщества
Важное нововведение — это сообщества. Они позволяют объединять проекты разных специалистов и удобны для организации командной работы в больших компаниях. Сообщества позволяют централизованно управлять проектами и сопровождать их внутри DataSphere, делиться ресурсами и моделями, а также учитывать разные роли членов команд как при коммерческом, так и при учебном применении проекта.
Проекты легко ассоциировать с разными сообществами и делиться их частями с пользователями из других команд. Например, команда дата-сайентистов, которая работает с распознаванием голоса, может поделиться частью своих акустических моделей с другими.
Для обсуждения проекта администратор сообщества может добавить ссылку на чаты.
Навигация в новом интерфейсе построена по принципу «хлебных крошек»: можно удобно переключаться между ресурсами проекта и отдельными проектами. Навигация сохраняет контекст, поэтому в первую очередь показываются сообщества, проекты и ресурсы, с которыми пользователь недавно работал.
Кому это полезно
Кто может пользоваться сообществами:
Data-инженер;
специалист по Data Science;
DevOps-инженер;
разработчик;
преподаватель, который занимается со студентами;
пользователь для продакшн-команд;
аналитик;
менеджер.
Принципиально новая роль — DevOps-инженер. Для DevOps-инженера в новом интерфейсе существует свой набор инструментов: дашборд с графиками и мониторингами, возможность анализировать логи и искать ошибки.
Менеджеры проектов и аналитики в новом интерфейсе теперь видят, сколько ресурсов тратит команда проекта и на что именно. В будущем появятся готовые блоки для вычислений без написания кода, возможность построить графики или посмотреть аналитику из разработки.
Будущее
Новый интерфейс и новые возможности Yandex DataSphere выведут работу дата-сайентистов на новый уровень — сильно повысят скорость разработки и производства моделей. Мы уже обновили JupyterLab® на новую версию, однако опрос пользователей показал, что не все из них предпочитают эту среду разработки. Очень скоро мы добавим альтернативы, например, VS Code. Эта популярная IDE поддерживает много языков программирования, позволяет искать по коду и перерабатывать его.
Также в новой версии будут предусмотрены инструменты автоматизации: запуск вычислений по расписанию и по событиям. Они позволят строить пайплайны, которые автоматизируют поставку данных, сбор датасетов и обучение моделей.
Мы обеспечиваем постепенную миграцию со старого интерфейса DataSphere, поэтому не стоит беспокоиться, что ваши старые модели пропадут. У вас будет время перенести все проекты.
Новый Yandex DataSphere уже доступен, и вы можете использовать все его возможности. Обсуждайте изменения в Telegram-чате, следите за новостями и релизами в нашем блоге.