Мы выпускаем новый сервис Yandex Query и новую версию Yandex DataSphere, реализовали множество улучшений в наших управляемых сервисах баз данных, добавили в сервис визуализации и анализа данных DataLens новые коннекторы, графики и многое другое. Продолжает развиваться и сервис Data Transfer, который решает задачи миграции и поставки данных в облако.

Анонсы и запуски Data Platform
Запуск сервиса Yandex Query, новая версия Yandex DataSphere, новые возможности Yandex Data Transfer и обновления в наших управляемых сервисах баз данных.
22 сентября 2022 г.
10 минут чтения
Группа «Платформа данных» в 2022 году остаётся одной из самых быстро растущих — только в первом полугодии потребление сервисов увеличилось в 2,5 раза. Пользователи применяют управляемые сервисы платформы для реализации комплексных сценариев по передаче, обработке и хранению данных, а также строят аналитические дашборды и запускают обучение моделей машинного обучения.
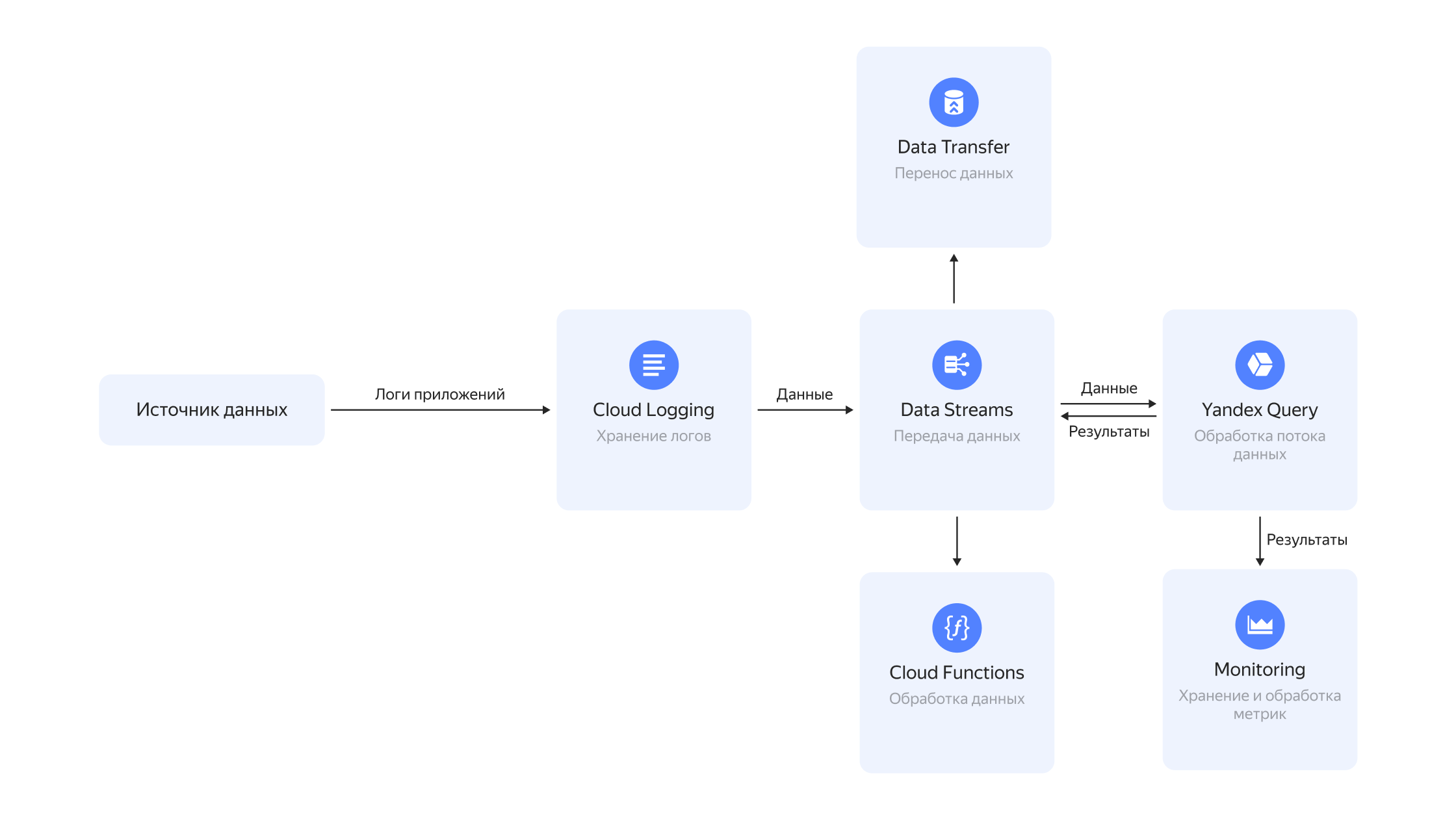
Yandex Query
В Yandex Cloud появился новый управляемый сервис для выполнения аналитических и потоковых запросов к неструктурированным и частично структурированным данным — Yandex Query. С Yandex Query компании смогут упростить и ускорить весь цикл работы c большими массивами данных. А за счёт унификации аналитической и потоковой обработки выполнять анализ данных в реальном времени становится ещё проще. Сервис находится на стадии Preview и не тарифицируется.
Yandex DataSphere

В этой статье мы расскажем:
Мы выпустили новую версию сервиса Yandex DataSphere. Наша команда создала не просто новый интерфейс, а продвинутое полноценное интегрированное рабочее место для дата-сайентиста с возможностью сохранять и воспроизводить результаты исследований, вести командную работу, расширяя возможности стандартных для индустрии инструментов, таких как JupyterLab. Интерфейс проектировался на основании исследования пользовательского опыта и обратной связи наших клиентов. Все подробности читайте в статье «Новый Yandex DataSphere — вышли за пределы JupyterLab®».
Yandex Data Transfer
Yandex DataSphere
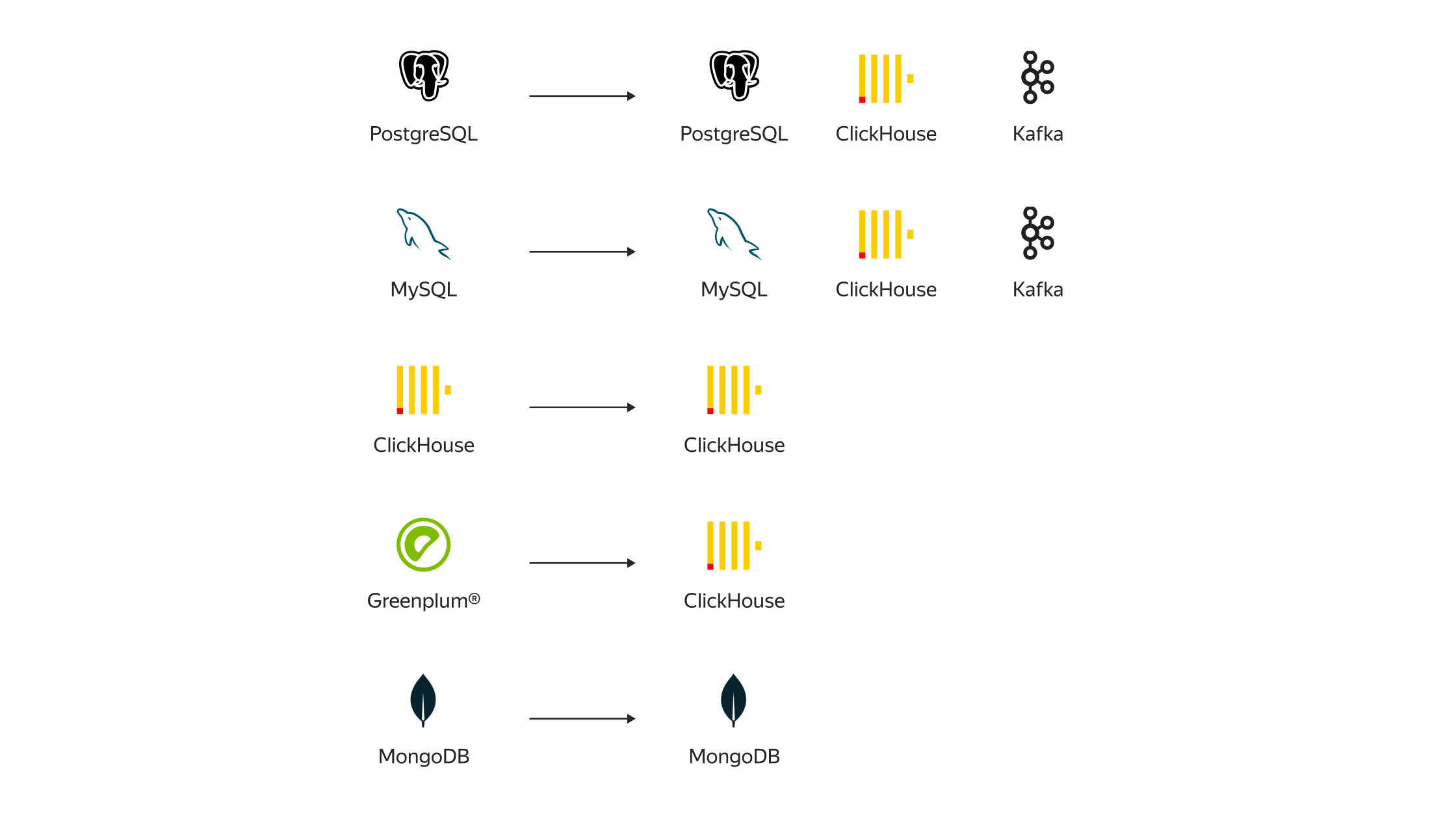
Мы активно работаем над нашим сервисом логического переноса данных между СУБД, объектными хранилищами и брокерами сообщений. Сегодня мы анонсируем выход новых возможностей Data Transfer, новых пар, сценариев и типов трансферов.
Новые возможности:
-
Поддержка security групп.
-
Отдельная роль для организации трансферов через интернет.
-
Поддержка переноса партицированных таблиц.
-
Ускорение снепшотов. Шардированые активации.
-
Трансформации данных.
-
Регулярные снепшоты и режим инкрементальной наливки.
Новые пары
Новые сценарии
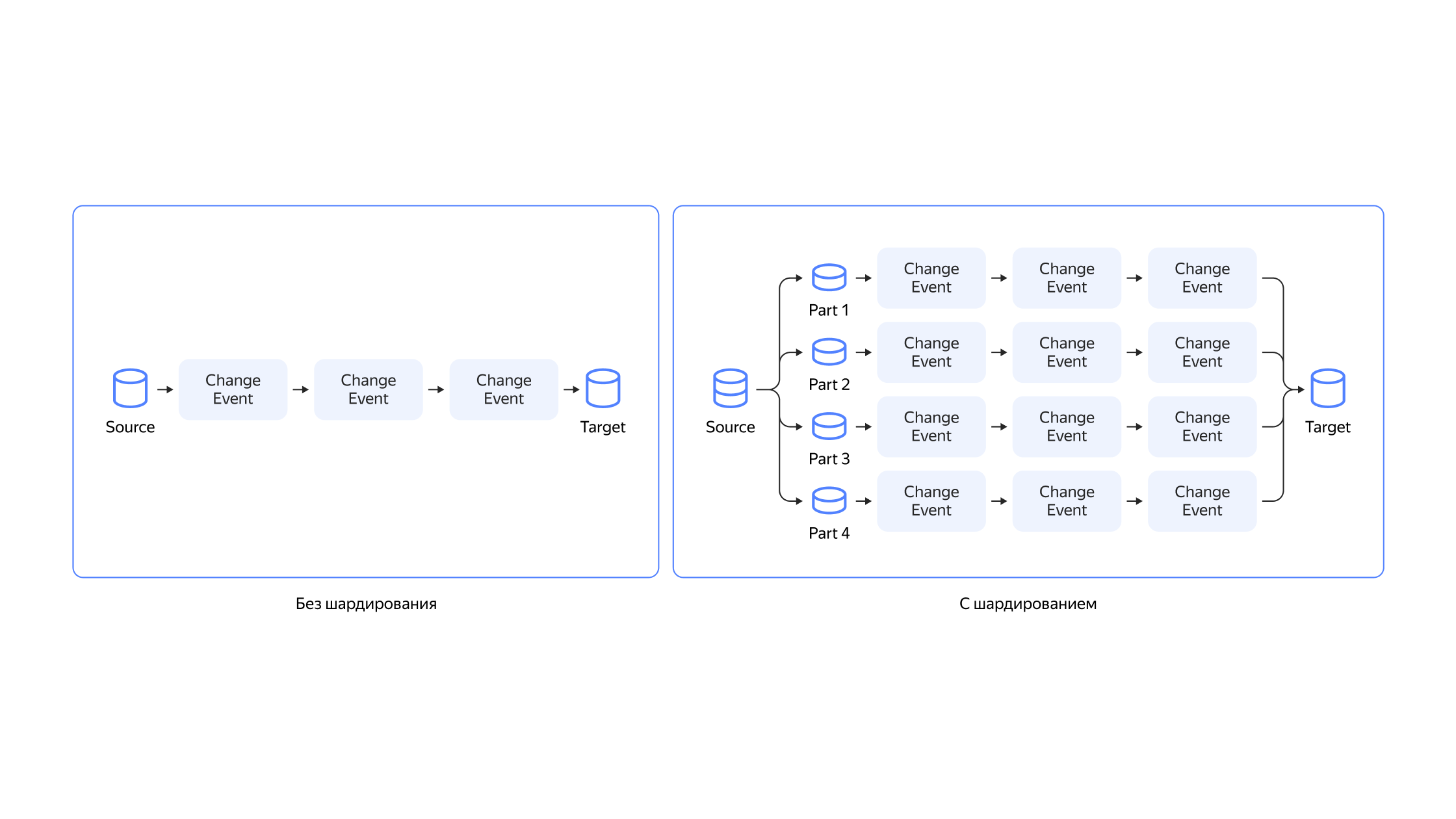
Data Transfer в процессе переноса данных использует подход CDC — change data capture, но до сегодняшнего дня эта функциональность была скрыта от глаз пользователей. Теперь подписаться на изменения в публичном формате debezium можно прямо в сервисе, в результате вы получите потов change event в топиках YDS или Kafka по вашим MySQL и PostgreSQL базам. Ваши приложения также могут подписаться на эти топики и прямо в продакшне использовать их для своих нужд.
Новые типы трансферов
Раньше у нас были следующие типы трансферов:
-
Копирование
-
Реплицирование
-
Копирование и реплицирование
Теперь Копирование можно сделать регулярным прямо в трансфере, а также регулярным с доливкой только тех строк, которых не было в прошлой итерации. Это позволяет без доступа к логам репликации организовать трансфер данных с минимальной задержкой, которая необходима для многих задач.
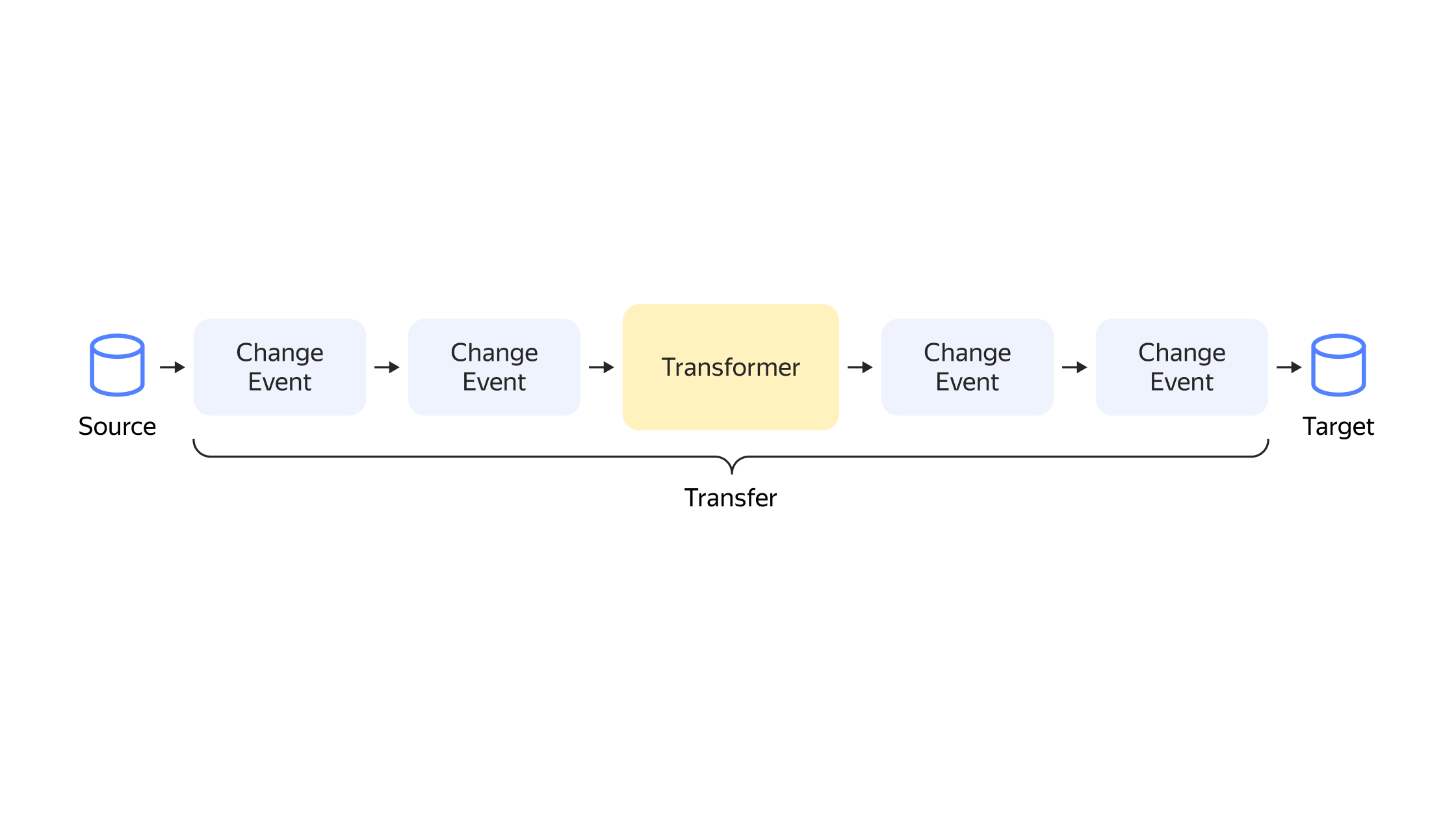
Трансформеры
Появляется новая настройка трансферов — трансформер — произвольная функция, которая может быть вызвана над потоком changeItems.
Например, теперь можно отфильтровать поле или переименовать таблицу.
Шардированые активации
В Data Transfer появилась возможность с большей параллельностью переносить исторические данные, ускоряя этот процесс. Например, базы MongoDB могут распараллеливаться по коллекциям, базы Greenplum — по сегментам, а базы PostgreSQL — не только по таблицам, но и внутри таблиц, если таблица соответствует определённым условиям.
Yandex DataLens
Yandex Data Transfer
DataLens сегодня — это больше 20 000 пользователей внутри Яндекса, больше 25 000 активных внешних экземпляров за последний год и рост активности пользователей в 6,9 раз.
Новые подключения:
-
Битрикс24
-
Yandex Query
-
YDB
-
Новый файловый коннектор
-
Yandex Мониторинг
-
Prometheus
Новые возможности в чартах:
-
Комбинированные диаграммы
-
Секция сплит
-
Линейные индикаторы в таблицах
-
Деревья Parent-Child
-
Условное форматирование
-
Градиентная закраска
-
Форма линий
-
Ширина столбцов в таблицах
-
Перенос текста в таблицах
-
Итоги в таблицах
-
Итоги в сводных таблицах
-
Кластеры для карт
-
Инспектор запросов

Новые возможности в дашбордах:
-
Параметризация
-
Автообновление
-
Операторы в селекторах
-
Настройка мобильной вёрстки
-
Публикация без материализации
-
Встраивание публичного дашборда
-
Поддержка тёмной темы

С этими и многими другими возможностями DataLens вы можете ознакомиться на обновленном демо-дашборде.
Обновления в управляемых сервисах платформы данных
Yandex Data Proc
Сервис для обработки многотерабайтных массивов данных с использованием инструментов с открытым исходным кодом, таких как Apache Spark™, Apache Hadoop®, Apache HBase, Apache Hive, Apache Zeppelin и других сервисов экосистемы Apache®. Новое за год:
-
Создание master-ноды с публичным IP-адресом.
-
Создание кластеров на сетевых нереплицируемых дисках размером до 8ТБ.
-
Реализована возможность отмены заданий, результат которых уже не важен.
-
Добавили легковесные кластеры Apache Spark без HDFS и DataNodes. Такие кластеры могут быть особенно удобны для запуска задач машинного обучения и подготовки витрин, так как они поднимаются быстрее и с меньшими затратами.
-
Доступна для тестирования версия образа 2.1 с Hadoop 3.3.2, Spark 3.2.1 и обновлениями других компонентов.
-
Стала доступна поддержка скриптов инициализации, которые могут быть полезны для автоматической установки или обновления ПО, необходимого для запуска заданий.
Yandex Managed Service for Greenplum®
Сервис для управления кластерами массивно-параллельной СУБД Greenplum® стал доступным для всех пользователей.
-
Новая версия 6.19 с исправлением известных ошибок.
-
Оптимизировано создание резервных копий за счёт особой обработки append-only сегментов.
-
Управление сервисом через CLI и Terraform.
-
Возможность изменения размера хранилища, в том числе для быстрого локального хранилища, а также добавление сегментов в кластер.
-
Работа с внешними источниками данных через PXF. Доступно подключение таблиц следующих внешних источников: Apache Hive, ClickHouse, HBase, HDFS, MySQL, Oracle, PostgreSQL, SQL Server, бакеты Object Storage.
-
Поддержка расширения pgcrypto, diskquota и других.
Yandex Managed Service for ClickHouse
-
Гибридное хранилище — возможность хранить данные ClickHouse в холодном S3-хранилище, что на порядок снижает стоимость использования решения. Для кластеров с гибридным хранилищем появились дополнительные storage policies: «local» и «object_storage». Политика «local» позволяет хранить данные только на локальном/сетевом диске, а политика «object_storage» — только в объектном хранилище. Возможность хранения данных в гибридном хранилище доступна всем пользователям.
-
ClickHouse Keeper — новый сервис для репликации данных и выполнения распределенных DDL-запросов, реализующий совместимый с ZooKeeper клиент-серверный протокол. В отличие от ZooKeeper, ClickHouse Keeper не требует для своей работы отдельных хостов, а выполняется на хостах ClickHouse, поэтому такая отказоустойчивая конфигурация обойдется дешевле.
-
Новые версии ClickHouse: 22.3 LTS, 22.5.
-
Восстановление шардированного кластера из резервной копии целиком.
Yandex Managed Service for PostgreSQL
-
Новые расширения: pg_cron, pgcompacttable, clickhouse_fdw, orafce, pg_qualstats, hypopg.
-
Новые версии PG14 и 14-1C, а также обновление со старых версий.
-
Релиз Odyssey 1.3 и возможность создания новой базы из шаблона.
Yandex Managed Service for MySQL®
-
Приоритеты хостов для бэкапов.
-
Возможность задавать приоритет выбора мастер хоста в случае смены мастера.
-
Управление настройками сервиса диагностики производительности во всех интерфейсах: CLI, Terraform, UI консоль.
-
Ускорен процесс восстановления реплики из резервной копии за счёт использования многопоточности при сжатии/шифровании бэкапа.
Yandex Managed Service for Apache Kafka®
-
Новые версии Kafka 3.0, 3.1.
-
Управление топиками через Terraform.
-
Новый коннектор: S3 Sink.
Yandex Managed Service for MongoDB
- Поддержка новой версии MongoDB 5.0.
Yandex Managed Service for Redis™
- Управление настройкой персистентности. Отключение персистентности увеличивает производительность кластера, но повышает риск потери данных.