Например, сервис Yandex DataSphere. Благодаря ему можно быстро организовать цикл машинного обучения в облаке и запускать ML‑модели в эксплуатацию без необходимости управлять инфраструктурой.

Компьютерное зрение: от распознавания текста до изучения космоса
Расскажем, как алгоритмы компьютерного зрения позволяют решать конкретные задачи в самых разных сферах.
27 мая 2022 г.
15 минут чтения
Краткий пересказ YandexGPT
- Компьютерное зрение — это научная область, связанная с анализом изображений и видео, которая использует технологии машинного обучения для распознавания визуальных образов.
- Компьютер видит не так, как люди, и нуждается в обучении для идентификации объектов на изображениях.
- Для обучения моделей компьютерного зрения используют большие базы данных и датасеты, на которых модели учатся распознавать закономерности.
- Обучение моделей часто происходит в облачной инфраструктуре для оптимизации ресурсов и ускорения процесса.
- Компьютерное зрение применяют в различных областях: распознавании текста, поиске изображений, модерировании контента, изучении космоса, развитии биометрии, 3D-анализе, сельском хозяйстве, видеоаналитике.
- Процесс обучения модели компьютерного зрения включает сбор данных, выделение характеристик объектов, анализ изображений и дообучение при необходимости.
- Полный цикл машинного обучения в облаке включает классификацию изображения, локализацию объектов и построение изображения.
Компьютерное зрение (computer vision, CV) — это научная область, связанная с анализом изображений и видео. Специалисты ищут всё более совершенные способы обучить компьютер правильно видеть и извлекать информацию из увиденного. Казалось бы, это так просто: научить искусственный интеллект распознавать визуальные образы. Но не тут‑то было.
Компьютер видит не так, как люди. У него нет нашего жизненного опыта и способности так же легко идентифицировать объекты на изображении. Он не способен отличить дом от дерева, не имея каких‑то исходных данных. Чтобы научить компьютер видеть и понимать, что находится на изображении, люди используют технологии машинного обучения.
Для этого собирают большие базы данных, из которых формируют дата‑сеты. Выделив признаки и их комбинации для идентификации похожих объектов, можно натренировать модель машинного обучения распознавать нужные типы закономерностей. Конечно, даже после загрузки нескольких дата‑сетов модели могут неверно распознавать некоторые объекты. Если такое случается, модели дообучают на новых наборах данных.

ML‑проекты могут потреблять значительное количество ресурсов, поэтому обучение часто проходит с использованием облачной инфраструктуры.
В этой статье мы расскажем:
Когда именно возникла идея компьютерного зрения, точно неизвестно. Считается, что одной из первых статей в научном журнале, так или иначе затрагивающих эту тему, была публикация Receptive fields of single neurons in the cat’s striate cortex. Её написали в 1959 году Дэвид Хьюбел и Торстен Визель, нейропсихологи из медицинского института Уилмера в США. В своей работе они изучали свойства нейронов зрительной коры кошек. И заметили, что зрительный опыт способен влиять на эти нейроны.
В это же время в схожем направлении думал и профессор Массачусетского технологического института Лоуренс Робертс. Он был уверен, что можно научить компьютер видеть, создал систему распознавания форм предметов и защитил в МТИ докторскую диссертацию по этому направлению.
И действительно, очень скоро компьютеры научились распознавать статичные изображения, в 80‑х годах появились теории систем распознавания движущихся объектов на видео, а в 90‑х учёные работали над прототипами беспилотных автомобилей.
Люди поняли, что технологии компьютерного зрения могут использоваться везде, где есть какие‑либо изображения. А благодаря развитию интернета появились массивы оцифрованных изображений, которые можно было анализировать. Это позволило обучить компьютер. Сначала — распознавать текст на сканах документов. Постепенно задачи усложнялись. Так технологии дошли до обнаружения лиц и их почти мгновенного распознавания на фото и видео.

Где используется компьютерное зрение
Распознавание текста
Распознавание текста — это один из самых первых проектов Yandex Cloud. Сложность задачи заключается в том, что у изображений разное качество. Нестандартные шрифты, языки, дизайн — компьютер должен уметь читать любые слова и предложения. Если на начальном этапе программа распознавала текст отсканированного документа, то позднее добавились фотографии этих же документов (порой нечёткие), ценники, этикетки и т. д. Причём пользователям нужно, чтобы текст распознался быстро и точно. А если он ещё и с иностранного языка будет переведён на русский или любой другой — то вообще хорошо.
Решение Яндекса позволяет на лету распознавать, переводить и искать в интернете текст с самых разных объектов. Подробнее об этом можно прочесть в статье о том, как Яндекс создавал технологию оптического распознавания текста OCR.

Поиск изображений
Наверняка вы не раз пользовались поиском Яндекса по картинкам. На раннем этапе развития технологии искать приходилось с помощью текстового описания, но теперь достаточно сфотографировать объект, чтобы поисковая система выдала похожие варианты. Это стало возможным благодаря технологии машинного обучения с использованием многослойных нейронных сетей, которые самообучаются на больших дата‑сетах с изображениями.
Чтобы такой поиск был эффективен, индексируются изображения, ранее загруженные в интернет. Для каждого изображения компьютер строит цифровые представления, формирует структуру данных: по ней будет вестись поиск. С изображением, которое загрузил пользователь, происходит то же самое, после чего в базе данных ищутся такие же или похожие картинки. Умная камера Яндекса умеет находить по фото даже товары в интернет‑магазинах. Из других решений компьютерного зрения, предлагаемых Yandex Cloud, можно выделить определение качества изображения и кодирование файла в Base64.
Модерирование изображений
С каждым годом пользователи загружают всё больше контента. Контролировать миллионы фото и видео вручную невозможно. Но необходимо фильтровать их, выявляя материалы для взрослых и шок‑контент. Здесь снова приходит на помощь компьютерное зрение. Решение модерирования изображений, предложенное Yandex Cloud, позволяет быстро обнаруживать публикацию нежелательного контента: материалов для взрослых, объектов, защищённых авторским правом, и т. д.
Почему это важно? В качестве примера опишем реальный кейс. Дети пользуются многими интерактивными мобильными приложениями. Например, приложение Тролли. Караоке с элементами дополненной реальности за несколько месяцев после запуска установили более 2 млн раз, туда загрузили более 15 тыс. видеозаписей. Вручную отслеживать такой поток контента практически невозможно.

На помощь пришло объектное хранилище Yandex Cloud и сервис Yandex Vision, отвечающий за распознавание элементов, которых не должно быть в кадре. В основе сервиса лежит анализ изображений с помощью моделей машинного обучения. Компьютерное зрение оценивало, насколько загруженные ролики соответствуют правилам, распознавало текстовый ненормативный контент, появляющийся на видео. А за проверку аудиодорожки отвечал SpeechKit — сервис, на основе которого работает Алиса. Получившаяся умная система премодерации защитила детей от нежелательного контента.
Изучение космоса
Снимки со спутников и телескопов долгое время анализировали люди. За многолетнюю историю наблюдения за космосом накопилось огромное количество данных из самых разных источников. И в этих данных может содержаться немало ценной информации, которую просто не заметили. Например, в декабре 2017 года астрономы, используя искусственный интеллект, проанализировали данные, собранные телескопом «Кеплер». Компьютерное зрение увидело то, что не заметил человеческий глаз: солнечную систему с восемью планетами.
Развитие биометрии
Изображение лица, радужная оболочка глаза, отпечаток пальца могут служить отличными идентификаторами человека. Но для этого нужна точность и производительность компьютера. Благодаря совершенствованию алгоритмов компьютерного зрения стала возможной разблокировка телефона по отпечатку пальца, платежи FacePay. Более того, компьютерное зрение способно распознавать даже лица людей, которые носят маску.
Яндекс представил технологию распознавания лиц ещё в 2012 году, а в 2019 году запустил облачный сервис Yandex Vision с технологиями компьютерного зрения для сторонних разработчиков. С помощью сервиса можно отметить людей на фотографии, найти все фото с портретами, автомобильные номера или шаблоны документов (например, паспорта) в большом дата‑сете.
3D‑анализ
Реконструкция зданий и других объектов по изображению — это ещё одна интересная задача, которая решается благодаря нейронным сетям. Загрузив в компьютер фотографии разрушенного объекта, на выходе можно получить реконструированную модель. Хорошим примером может стать решение Instance Segmentation. В данном случае технологии компьютерного зрения упрощают перенос любых графических данных в 3D‑модели и оптимизируют создание новых продуктов. Пока не удалось добиться, чтобы данные передавались в режиме real‑time. Но в перспективе это решение может перерасти в онлайн‑сканирование объектов и пространств.
Укрепление сельского хозяйства
Качество и количество урожая, увеличение поголовья скота зависят от многих факторов. Быстро проанализировать их способен только компьютер. Сбор урожая тоже можно поручить искусственному интеллекту. Например, испанская компания Agrobot создала автоматический сборщик клубники. Устройство умеет самостоятельно ориентироваться в пространстве и оценивать зрелость ягод с помощью технологий компьютерного зрения. А решение Sonoma позволяет почти без участия человека выращивать огурцы. Обученный компьютер через систему камер и датчиков следит за состоянием почвы и рассады и управляет ирригацией, подкормкой, температурным режимом и другими параметрами, необходимыми для созревания урожая.
Видеоаналитика
На дорогах, в метро и наземном транспорте, в офисах, подъездах и куче других мест вы наверняка видели камеры. Они отвечают за контроль движения автомобилей, мониторинг людских потоков, оповещение об инцидентах и т. д. Современные технологии компьютерного зрения позволяют идентифицировать преступника в большой толпе, вычленить нарушителя в потоке машин, увидеть брак на конвейерной ленте завода. Благодаря технологиям глубокого обучения компьютеры теперь умеют проводить геологические исследования не хуже людей!
Говоря о компьютерном зрении, можно вспомнить системы беспилотных автомобилей, контроль размеров или наполняемости упаковок на пищевом производстве, мониторинг зазоров и других характеристик деталей на автосборочных конвейерах и т. д.
После обучения компьютерные системы способны на многое. Но как проходит обучение?
Как обучается модель компьютерного зрения
Для обучения компьютера собирается массив данных, с помощью которого можно выделить характеристики, присущие тем или иным объектам. Чтобы компьютер мог находить котиков на фото, ему нужна обучающая выборка. Это дата‑сет с изображениями котов (положительные примеры), который разбавлен картинками без котов (отрицательные примеры).
Во время обучения компьютер анализирует изображения, выделяя признаки и комбинации признаков, которые позволяют понять, что на картинке кот. Чем больше и разнообразнее коллекция картинок, тем точнее искусственный интеллект научится распознавать объекты. Если машинное обучение прошло успешно, компьютер справится с задачей распознавания. Если процент ошибок высок, можно провести дообучение на других дата‑сетах.
ElectroNeek: опыт применения Yandex Vision
Обучающие дата‑сеты обычно очень крупные, поэтому обучение модели компьютерного зрения может занимать много времени. Чтобы ускорить процесс, такого рода задачи разумнее выполнять в облаке с помощью виртуальных графических процессоров. Производительность GPU выше стандартных CPU, а масштабирование позволяет быстро получить объём ресурсов, необходимый для полноценного обучения модели. Например, для создания систем компьютерного зрения можно использовать сервис ML‑разработки Yandex DataSphere, в котором есть инструменты и динамически масштабируемые ресурсы, необходимые для полного цикла разработки машинного обучения.
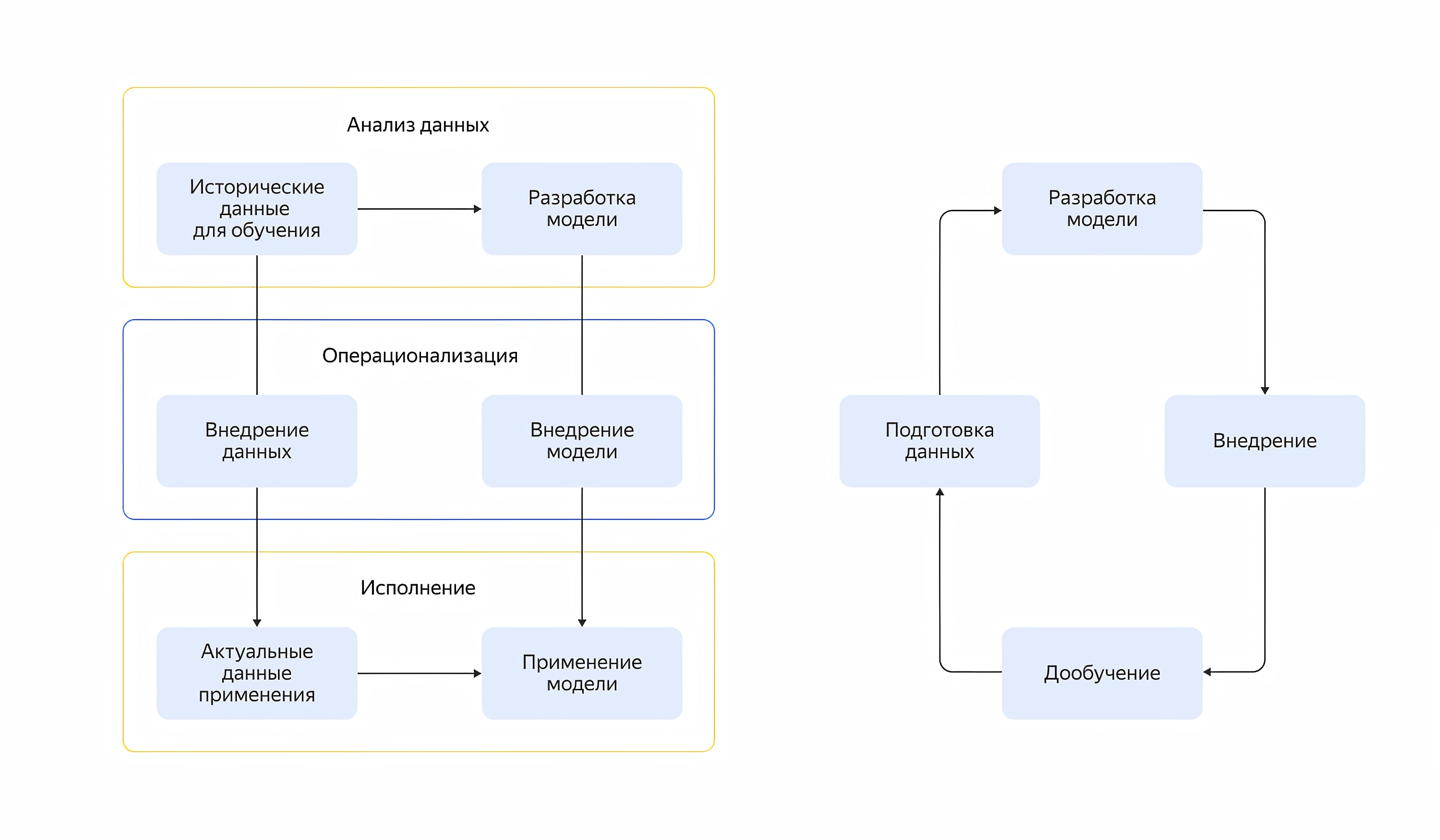
Как выглядит полный цикл машинного обучения в облаке
Если сильно упрощать, то любая система компьютерного зрения при анализе изображения проходит через три этапа:
- Классификация изображения. Компьютер присваивает картинке некий класс из заранее известных.
- Локализация конкретного объекта. Чем больше объектов на изображении, тем сложнее требуется нейросеть.
- Построение изображения. Программа убирает шум и повышает качество картинки, выделяя доминирующие и малозначительные объекты.
Каждый этап сложен, ведь компьютер не понимает, что на изображении важное, а что не очень. Поэтому сначала картинка проходит через внутренние алгоритмы, заложенные разработчиками. Так компьютер получает начальные сведения об изображении. Затем компьютер находит объекты и их границы. Для этого есть разные способы. Например, можно использовать размытие по Гауссу, когда изображение размывают несколько раз, выявляя самые контрастные фрагменты. Эти значимые места в дальнейшем считаются объектами.
Значимые места компьютер при помощи любого из популярных алгоритмов (например, SIFT, SURF, HOG) описывает в числовом виде. Такая запись называется дескриптором. Она позволяет полно и точно сравнить фрагменты изображений, не используя сами фрагменты. Но так как сравнение — это тяжёлая вычислительная операция, то дескрипторы кластеризуют: делят на группы. В каждой группе находятся дескрипторы разных изображений, но с общими характеристиками.
Кластеризация и следующее за ним квантование (обобщение) дескрипторов уменьшает объём данных, которые приходится обрабатывать компьютеру. А заодно позволяет быстрее распознавать объекты и сравнивать изображения.
Yandex Vision
Сервис компьютерного зрения — это эффективное и надёжное решение бизнес‑задач, связанных с распознаванием текста (OCR), документов, автомобильных номеров, обнаружением лиц и классификации изображений.
Yandex DataSphere
Сервис для ML-разработки предоставляет все необходимые инструменты и динамически масштабируемые ресурсы для полного цикла разработки машинного обучения.
Если вам понадобится помощь или совет с разработкой систем компьютерного зрения или другими сервисами Yandex Cloud, обратитесь к нашим специалистам. Вы также можете воспользоваться услугами партнёров Yandex Cloud, чтобы подобрать технологию для решения задач своего бизнеса.